
A silent production floor is the ultimate sign of trouble. Every moment the line isn’t running, productivity drops and costs climb.
The financial consequences are staggering. Siemens research reveals that an average plant loses 25 hours monthly to unplanned downtime. And for manufacturers, the cost of a single hour of being offline can vary between $39k (for FMCG) and $2 million (for the automotive industry).
These figures underscore a critical truth — minimizing downtime is not just a maintenance task, but a core business strategy.
To effectively combat manufacturing downtime at your facility, you need to identify where the problems hide. This guide will point you in the right direction by exploring the most common causes of downtime in manufacturing.
Identifying the most common causes of manufacturing downtime
Before you can start reducing downtime, you have to understand what’s causing it.
But many plants find it challenging to get clear data. Ideally, you would have access to a CMMS, MES, or OEE tracking software to regularly analyze production and downtime metrics. It’s the simplest way to find patterns that point to recurring problems.
In the following sections, we’ll break down the eight most common causes of downtime in manufacturing, with practical tips to help you eliminate them. We will include both planned and unplanned events, with more focus on the latter. After all, that’s where the biggest losses happen.

1. Equipment breakdowns
When machines stop, so does production. Equipment breakdowns are one of the most disruptive and expensive causes of unplanned downtime. They come in the form of mechanical failures, electrical issues, problems with hydraulics, and similar.
Here’s a crucial thing to keep in mind: frequent asset breakdowns are almost always symptoms of deeper issues.
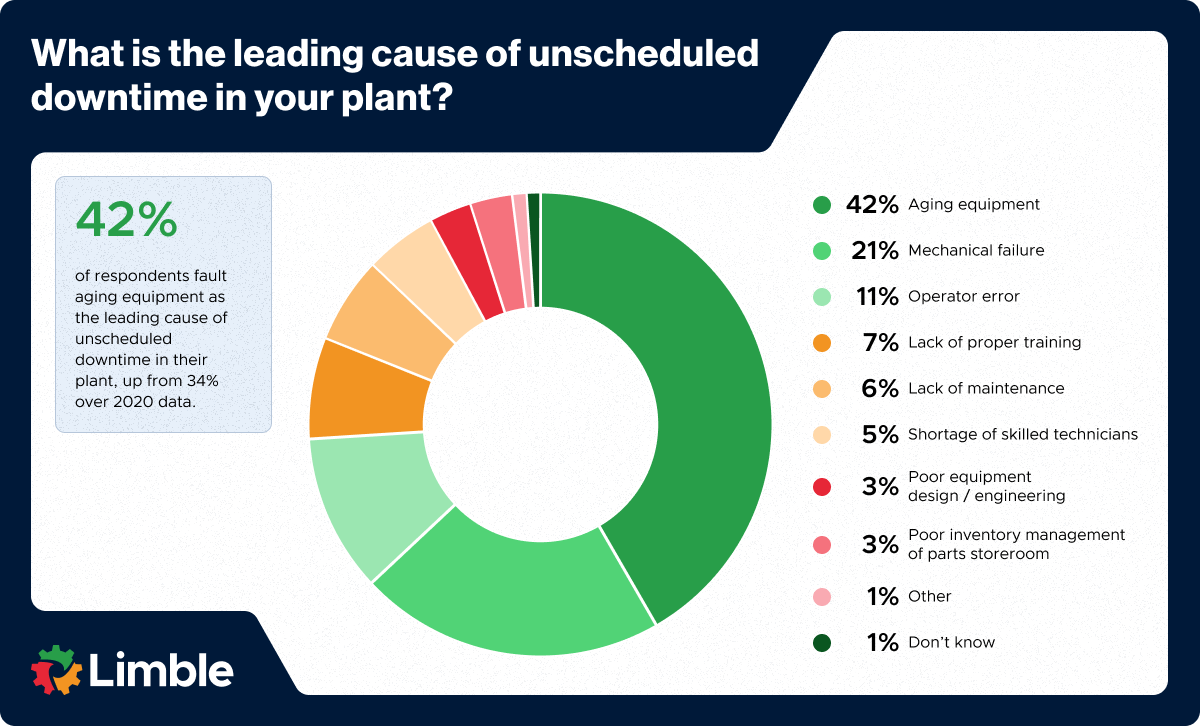
To find and eliminate underlying issues, the reliability team can jump in to perform root cause analysis. That isn’t always necessary, as some failure reasons are fairly obvious. In fact, according to the Plant Engineering maintenance study, aging equipment, mechanical failures, and operator errors cause about three-quarters of all unplanned downtime.
A modern CMMS like Limble can help you significantly reduce machine breakdowns at your facility. Here’s how:
- Track failure history across each asset to identify patterns.
- Log root cause analysis after every major breakdown.
- Schedule preventive maintenance based on real-time equipment condition and performance data.
- Use predictive analytics to predict failures and perform timely maintenance.
- Generate automated reports that highlight which machines experienced the most downtime.
 When you start logging and analyzing this data consistently, you’ll stop reacting to breakdowns — and start preventing them.
When you start logging and analyzing this data consistently, you’ll stop reacting to breakdowns — and start preventing them.
2. Human errors
Not every breakdown is mechanical. Sometimes, it’s a mistake made by a person that brings everything to a halt.
While it’s easy to blame the individual, human error is often a symptom of a broken system — primarily due to a lack of standardization and insufficient training.
An incorrect installation, a missed step in a complex repair, or a misdiagnosed problem can lead to repeat failures, damaged equipment, and extended machine downtime.
There are many effective ways to prevent human error:
- Standardize procedures: Create clear SOPs, checklists, and safety guidelines for routine or complex maintenance tasks, repairs, and changeovers. Then attach them to the relevant Work Orders.
- Provide instant access to information: Empower technicians by giving them mobile access to asset histories, technical manuals, schematics, and photos right at the job site.
- Capture and share team knowledge: When a novel problem is solved, use your CMMS to document the solution with notes and pictures in the asset’s history. This turns valuable individual experience into a searchable, permanent resource for the entire team.
- Encourage communication: Make it easy for techs and operators to flag unclear steps or ask for help.
3. Poor maintenance practices
The most impactful maintenance mistake manufacturers make is over-reliance on reactive maintenance. It invites chaos onto the production floor, leading to more downtime, higher repair costs, and reduced equipment lifespan.
But being reactive is far from the only problem. Many plants struggle with poor maintenance practices that allow minor issues to snowball into major disruptions:
- Unclear planning and scheduling: Without a structured system, work orders get delayed, critical PMs are missed, and unrealistic job plans lead to a massive amount of rescheduling.
- Slow emergency response times: When techs don’t have access to asset histories or repair instructions, troubleshooting takes much longer than it should.
- Lack of documentation: If maintenance logs are incomplete (or nonexistent), teams end up repeating work, misdiagnosing failures, or overlooking patterns that could prevent future downtime.
- Ineffective communication between teams: When Maintenance, Production, and Purchasing don’t communicate clearly, work gets duplicated, missed, or delayed. You get delays that could have been avoided with a quick heads-up or a shared calendar.
These problems are made worse by today’s labor shortage. With fewer experienced technicians on staff, there’s less time to plan, document, or step back and look at the big picture.
The fastest way to fix all of this is to implement a modern CMMS. It will help you standardize maintenance procedures, document everything, and stick to your preventive maintenance schedule.
4. Process bottlenecks
Do you ever notice materials backing up before a slow machine or operators idling while they wait for the following stations to catch up? A bottleneck will put a hard cap on your throughput.
If that happens often on your production floor, you can:
- Run a line balancing study: Measure cycle times at each station to see where the delays happen.
- Add capacity where needed: This could mean adding another operator, machine, or shift at the problematic step.
- Optimize the bottleneck process: Look for ways to streamline the work, improve tooling, or reduce waste.
- Automate repetitive tasks: If a slow station involves repeatable manual work, automation might be the answer.
- Buffer intelligently: Use WIP buffers or accumulation tables to keep upstream processes moving.

An example of an accumulation table. Source: Mobility Engineering
5. Changeovers and setup time
Every time your team switches a line, swaps a mold, or adjusts a machine for a new product run, production stops. That pause — whether it lasts 15 minutes or 2 hours — can be a major source of planned downtime.
In many plants, these transitions either take too long or are rushed (resulting in rework and trial-and-error adjustments).
Performing a simple time study is one way to uncover inefficiencies in your changeover process. While tracking and analyzing each step, look for:
- Long pauses between runs while waiting for instructions or approvals.
- Technicians wasting time searching for tools, parts, or fixtures needed for the setup.
- Inconsistent results — one shift nails the changeover, the next struggles.
- Extended ramp-up time due to poor calibration or missed steps.
Here’s how to fix those problems:
- Standardize the process: Create a step-by-step checklist for every changeover type.
- Organize tools and materials: Use shadow boards, kitting, or labeled carts to make setup items easy to find.
- Use SMED principles: Focus on reducing internal setup time and moving tasks “offline” where possible.
Speeding up changeovers without sacrificing quality should help you recover valuable production time.
6. Supply chain and MRO management issues
Supply chain and inventory problems often show up as unexpected downtime — a machine sits idle because a critical raw material hasn’t arrived, or a technician can’t complete a repair because the correct spare part isn’t in stock.
These delays are often the result of two things: poor MRO inventory management and unreliable suppliers.
In some cases, teams aren’t tracking parts usage closely enough and don’t reorder on time. In others, there’s no visibility into what’s actually in stock — so people assume something is available when it’s not.
Combine that with a vendor that consistently misses delivery windows, and all the planning in the world won’t save you.
Prevent these types of issues by:
- Using real-time inventory tracking: For example, Limble CMMS can automatically update stock levels as parts are used.
- Setting reorder points and alerts: Your inventory management system should warn you when stock falls below a set threshold.
- Auditing your inventory regularly: Don’t trust what’s on the shelf until you’ve verified it. Again, you can use Limble’s cycle count to audit parts inventory.
- Standardizing your parts catalog: Clear naming conventions and part numbers prevent confusion and double ordering.
- Vetting and diversifying your suppliers: Build relationships with reliable vendors — and have backups ready.
7. Software and system failures
Whether it is CMMS, MES, ERP, SCADA, or a specialized manufacturing solution, modern manufacturing runs on software. When those systems go down, production rarely remains unaffected.
For example, if your CMMS doesn’t sync with your inventory system, a technician might be sent to perform a repair only to find the part isn’t available. If your MES or SCADA stops updating in real time, operators may be forced to shut down equipment as a precaution.
To avoid software-related downtime, you’ll want to:
- Work with IT to create a software maintenance plan: Regular updates, backups, and health checks help avoid crashes, especially if the solution is hosted and run on local servers.
- Train staff on proper usage: Data entry and similar errors can lead to corrupted data or miscommunication.
- Use systems with offline capabilities: That way, work can continue during temporary network outages.
- Limit the number of systems you are using: Fewer disconnected tools = fewer integration problems.
- Choose vendors with strong support and uptime guarantees: Fast help during a critical issue can save hours of downtime. For reference, Limble has a 99.99% uptime record. You can track it live here.
8. Utility or environmental factors
Some causes of production downtime are outside your control — but that doesn’t mean you can’t prepare for them.
These events may be rare, but when they hit, the impact can be massive. A single power surge can knock out sensitive equipment. A flood can shut down operations for days. And a failed cooling system can trigger overheating and unexpected shutdowns across the plant.
Here’s how to reduce the impact:
- Have contingency plans in place: Identify your most vulnerable systems and create clear response procedures. For instance, use your CMMS to build standardized digital checklists for various emergency scenarios.
- Invest in backup power and surge protection: A backup generator can allow for safe shutdowns or partial operation.
- Monitor environmental conditions: Use sensors to track temperature, humidity, or water presence in sensitive areas.
- Improve resource forecasting for recovery: Use maintenance data to better forecast the critical spare parts, raw materials, and labor needed for recovery efforts.
- Document emergency contacts and escalation plans: A crisis is the worst time to hunt for a vendor’s phone number or a machine’s startup manual. Everyone should know who to call, what steps to take, and where to find critical information.
You can’t stop a storm or a grid failure — but with the right planning, you can minimize downtime and recover faster when it happens.
How Limble helps solve the root causes of production downtime
To stay ahead of downtime, you need systems that give your team visibility, control, and the tools to act before problems escalate.
That’s where Limble comes in. It replaces paper, spreadsheets, and guesswork with a centralized, easy-to-use platform built for modern maintenance teams.
Whether you’re dealing with aging equipment, labor shortages, or supply chain headaches, Limble helps you simplify your workflows and boost production uptime.
With Limble, you can:
- Prevent asset failure by automating work order scheduling and ensuring PMs get done on time.
- Streamline workflows by centralizing all work orders, asset information, communication, and planning in one place.
- Eliminate parts-related delays with real-time inventory tracking and automated reorder alerts.
- Reduce human error by equipping technicians with digital checklists, SOPs, and asset histories on their mobile devices.
- Maximize team productivity to get more done — even when you’re short-staffed.
More than 50,000 maintenance professionals trust Limble to reduce downtime, simplify their workflows, and keep teams connected.
Start for free today and see how you can replicate their success.
FAQ about manufacturing downtime causes
What is the difference between planned and unplanned downtime?
Planned downtime is scheduled and controlled — like routine maintenance, equipment upgrades, or changeovers. It’s expected and usually built into the production schedule.
Unplanned downtime happens unexpectedly due to equipment failures, errors, or supply chain disruptions. It’s more costly because it causes sudden interruptions and is harder to manage.
Which is the most common cause of unplanned downtime?
Equipment breakdowns are one of the most common and costly causes of unplanned downtime. These failures often stem from poor preventive maintenance, aging machines, or operator errors.
How do I calculate the cost of downtime for my facility?
There isn’t a completely accurate calculation. However, you can get a good estimate using this formula: Cost of Downtime = Lost Revenue + Lost Productivity + Recovery Costs
- Lost revenue: The profit from products you couldn’t make during the outage.
- Lost productivity: The wages paid to idle staff during the downtime.
- Recovery costs: Expenses for overtime labor, expedited parts shipping, and other emergency measures.
What is the first step to reducing unplanned downtime?
Start by tracking and categorizing every downtime event. Use a CMMS or digital downtime log to capture the what, when, and why of each incident. Once you have reliable data, you can spot trends, identify root causes, and prioritize the most common issues.
What is the best way to start tracking production downtime and OEE?
Start small:
- Define downtime categories (planned, unplanned, setup, etc.).
- Use a CMMS or spreadsheet to log every downtime event.
- Track three core OEE components — availability, performance, and quality.
As you build a habit of tracking, if you are not using it from the start, move toward automated tools that calculate OEE in real time and tie it to your maintenance workflows.