Fault Tolerance
Learn how fault-tolerant systems help optimize equipment reliability and availability for manufacturers.
What is fault tolerance?
Fault tolerance is a system’s ability to continue normal operations in the event of failures or malfunctions. These malfunctions may include power outages, technical glitches, and even potentially catastrophic system failures.
Why are fault-tolerant systems important?
The various approaches to fault tolerance all help organizations avoid the consequences of a single point of failure. Additional benefits of improving fault tolerance across your organization may include:
- Increased reliability: By reducing the likelihood and potential impact of system failures, fault tolerance boosts the reliability of your assets.
- Reduced downtime: Automated fault detection and recovery systems ensure that backup resources can be used to reduce unexpected downtime and minimize its direct and indirect costs.
- More secure data: Fault-tolerant systems can eliminate the risk of critical data loss or corruption by storing crucial information in backup locations and responding in the event of data breaches or hardware failures.
- Enhanced performance: Ensuring workloads are distributed for maximum efficiency, fault-tolerant systems can reduce bottlenecks to improve overall system performance.
Fault-tolerant systems contribute to a more resilient organization and play an important role in business continuity as a whole.
The Essential Guide to CMMS
Download this helpful guide to everything a CMMS has to offer.

Fault-tolerant systems vs. highly available systems
Availability and fault tolerance are both ways to make systems more reliable, maximize uptime, and achieve business continuity. The key difference between the two is that fault tolerance eliminates the possibility of service interruption altogether. Even assets with 99.999% availability (sometimes referred to as five nines-class equipment) will experience some downtime each production cycle.
Do you need fault-tolerant systems?
In some instances, systems require fault-tolerant designs to function as needed. For other systems, availability above a certain threshold will suffice. Whether you work toward fault tolerance or strive for high availability for a particular system will depend on your answers to these questions:
- How important is the component or system? If a given component or system is not critical to your organization’s normal operations, you may not need to make an investment in fault tolerance.
- How likely is it that this component or system will fail? Fault tolerance systems are generally unnecessary in instances where failure is extremely unlikely.
- How much will it cost to make a component or system fault-tolerant? Even when critical systems are vulnerable to failure, investing in fault tolerance is not always cost-effective.
Different levels of fault tolerance
Though fault tolerance is not typically measured with a percentage like availability, fault-tolerant systems can offer different levels of protection against disruptions.
- The simplest type of fault-tolerant technologies allow businesses to function in the event of power failures.
- At the next level, systems are capable of instantly switching to backup components in response to failures.
- High-level fault tolerance involves the use of numerous sensors or systems to continuously assess for signs of a fault or failure and trigger a corrective response.
- Fault-tolerant technology and redundancies may be built directly into processes and systems, automatically triggering backups when needed to provide the highest level of protection.
Fault tolerance techniques
A number of techniques help improve a system’s level of fault-tolerance and maintain continuous operations in spite of one or more failed components.
Redundancy
Redundancy-based fault tolerance involves duplication of mission-critical equipment, systems, or components to provide protection against failure.
An active redundancy uses multiple pieces of equipment that operate simultaneously. In the event that one piece of equipment fails, the other can make up the difference.
Passive redundancies involve backup components that only become operational once primary equipment fails. You’ll encounter two distinct types of passive redundancy.
- Operating passive redundancies: These involve equipment that is waiting on standby as a hot spare. The redundant component may operate under no-load conditions or serve a different function than the primary equipment. If the primary equipment fails, the standby equipment transitions to take over its function.
- Non-operating passive redundancies: These backup components are powered down until they need to replace the primary piece of equipment. Redundancies may go into operation automatically upon the failure of the primary system or require manual intervention.
Replication
Replication-based fault tolerance entails copying data to multiple systems. This promotes continuity in the event of a node failure. The higher the degree of replication, the more fault tolerance the system has.
Diversity
Diversity-related techniques for improving fault tolerance involve introducing new hardware, software, or network components into a system to make it more resilient. Leveraging a range of hardware vendors and selecting software written in multiple languages, for example, can improve diversity to mitigate the risk of failure.
Load balancing
A load balancing technique for improving fault tolerance involves distributing your organization’s workloads across numerous pieces of equipment. This allows activity to be spread across alternate production lines to maintain functionality in the event one line experiences a failure.
Components of a fault-tolerant system
Developing a fault-tolerant system requires effort at each stage in the equipment life cycle. Depending on its sophistication, the system may include some or all of the following components for detecting and responding to failures:
- Fault detection and display
- Fault diagnosis and containment
- Fault masking and compensation
Fault detection and display
Fault detection refers to a system’s ability to sense a fault and alert the appropriate individuals. This is the fundamental feature of any fault-tolerant system. All other components depend on the effectiveness of the fault detection process.
For example, a sensor in a tire pressure monitoring system (TPMS) can detect over- or under-filled tires and promptly alert the driver via the car’s dashboard. Detection and display is the acceptable tolerance level for this type of fault event. There is no automatic correction for the situation.
Fault diagnosis and containment
For more sophisticated systems and equipment, additional protections that trigger containment measures are included as part of the design. For example, a Distributed Control System (DCS) both monitors parameters through a set of sensors and performs diagnoses to locate and contain faults.
Imagine a pressure sensor within a system that detects petroleum products inside a vessel which are dangerously close to igniting or exploding. These sensors can trigger a pressure valve to activate and divert the high-pressure vapor to an exhaust stack.
Fault masking and compensation
Masking faults is often a useful technique for protecting equipment that can be monitored or controlled through Internet of Things (IoT) technology. Cybersecurity attacks pose a constant threat for these types of equipment. An attacker may attempt to introduce a fault by injecting false data into the system.
Incorrect data could mean that the control and monitoring systems designed to protect the equipment actually begin causing it to fail. Alternatively, false data may trick a system into believing that faulty assets are in normal working condition. Over time, the assets will deteriorate without triggering the appropriate alerts.
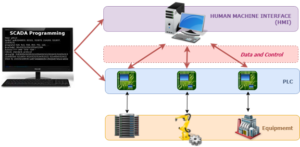
An example of a SCADA system.
Fault-masking ensures systems are designed to recognize incorrect information. For example, the circuit breakers in electricity grids are often controlled and monitored via Supervisory Control and Data Acquisition (SCADA). These systems monitor voltage and frequency parameters to promote stability across the power network. If an attacker attempts to inject false data, the system’s algorithms will respond by introducing additional data that “masks” the attacker’s efforts and keeps the grid reliable.
Want to see Limble in action? Get started for free today!
Analyzing fault tolerance
As an essential part of reliability engineering, fault tolerance requires careful examinations of all possible failure sources. Well-known techniques for analyzing systems include Failure Mode Effect Analysis (which takes a bottom-up approach) and the Fault Tree Analysis (which takes a top-down approach). More advanced methods like the Markov model analyze dependencies throughout the system to assess the probability of failures.
Introducing CMMS software to your team can help ensure they stay on top of corrective maintenance and develop systems that empower a more proactive approach to addressing faults across the organization.


