Reliability Centered Maintenance
Everything you ever needed to know about reliability centered maintenance.
What is reliability centered maintenance?
Reliability-centered maintenance (RCM) is a structured approach to maintenance work that prioritizes the cost-effective prevention of system failure. It uses a logical and structured process for organizations to identify critical assets and develop an effective and efficient maintenance plan for them that preserves operations and productivity.
Table of Contents
How is RCM is different from other types of maintenance
RCM is different from other maintenance strategies in two specific ways:
- RCM follows a structured framework for prioritizing systems and assets that need maintenance.
- Maintenance plans are designed to keep systems and operations functional, rather than to keep specific equipment running.
RCM provides a process for developing a maintenance program that provides an acceptable level of assurance that a system will keep functioning, while assuming an acceptable level of risk. In other words, it ensures just enough maintenance and upkeep to keep a process working, but no more. This helps minimize asset management costs and ensure a higher return on investment in maintenance activities.
The guiding principles of RCM
The primary function of maintenance is to fix things when they need fixing, right? RCM encourages a different approach by focusing on a different set of goals:
- Preserve a system’s operation and output
- Identify potential points of system or equipment failure
- Prioritize those potential failures by impact and cost
- Plan a maintenance strategy with tasks that directly address causes of failure
The most sophisticated – and efficient – asset management programs are based on a deep understanding of system functions and failures. Such knowledge enables you to select the best-fit maintenance strategy to prevent or predict each failure.
History of RCM and the types of organizations that use it today
Reliability centered maintenance originated in the aviation industry in the 1960s when research began to show that previous methods were insufficient and not as efficient as they could be.
While the aerospace, nuclear, and defense industries continue to be primary users of RCM, other asset-intensive industries such as oil and gas, railways, automobile, and food manufacturers are using RCM at increasing rates to reduce maintenance costs and improve overall equipment effectiveness (OEE).
The benefits of reliability centered maintenance
Industries using reliability centered maintenance report safety, reliability, cost, scheduling, and efficiency improvements across the board. Here’s why.
Safety is naturally prioritized
RCM requires an evaluation of possible failure modes and their risks to the business – primary among them are safety risks. By simply following the steps in the RCM process, organizations root out and address the hidden failures that pose safety risks.
Continuous improvement is elevated
For organizations practicing or moving toward continuous improvement, RCM is a natural fit. Because it involves regular analysis of failures, priorities, and performance, the maintenance program can be adjusted over time for increased effectiveness and ever-greater equipment availability.
Maintenance costs go down
As failures decrease, the repair costs decline. In addition, by focusing on only performing the maintenance tasks that provide the greatest return, total maintenance costs go down and production goes up. A common secondary benefit is often reflected in lower energy costs.
Targeted interventions simply work better
Reliability centered maintenance emphasizes cost-effectiveness by considering a systems specific and unique points of failure and applying a proportionate maintenance strategy. The process ensures that maintenance interventions are specifically targeted to the solutions they are trying to address, increasing the effectiveness of your team and the utilization of your maintenance resources.
The disadvantages of reliability centered maintenance
The primary challenge posed by reliability centered maintenance is in the investment it takes to achieve it. While RCM reduces long-term costs, maintenance costs may increase in the first 12 to 24 months due to the additional training, equipment, and implementation resources it requires. Once implemented, however, cost recovery occurs rapidly.
Nasa provides an interesting case study of the gains they experienced from implementing RCM in 1996. Between 1996 and 2000, Nasa estimated its cost savings from RCM to be $33,643,000, providing a return on investment (ROI) of 2.2. Nasa reports this ROI is consistent with that experienced in similar RCM implementations by British Petroleum and the Electric Power Research Institute (EPRI).
How to perform reliability centered maintenance
A typical RCM process comprises seven steps, which can be segmented into three distinct phases:
- Decision
- Analysis
- Action
In the end, you will have a fully formed reliability centered maintenance strategy that fully consideres all seven of the following questions established by SAE JA1011_199908 standards :
- What is the item supposed to do and what are its associated performance standards?
- In what ways can it fail to provide the required functions?
- What are the events that cause each failure?
- What happens when each failure occurs?
- In what way does each failure matter?
- What systematic task can be performed proactively to prevent, or to diminish to a satisfactory degree, the consequences of the failure?
- What must be done if a suitable preventive task cannot be found?
Here is how to establish a reliability centered maintenance program in seven detailed steps. For each, we’ll use an example of a centrifugal pump to provide context.
Step 1: Select the system or asset for your RCM program
Begin by assembling a team and together, choosing asset(s) or system(s) for your RCM program. Ideally, these will be assets or systems that are critical to your organization’s core operations and output.
Because of the intensive resources involved in the process, a criticality analysis is helpful in selecting an asset or system that is worth the effort.
Step 2: Define the functions and purpose of the system or asset
The objective of reliability centered maintenance is to preserve system function. Here, the team must define a complete list of all the functions the item or system performs to contribute to operations. This step should note any applicable performance standards.
Example: If a multi-stage centrifugal boiler water feed pump was the selected piece of equipment, our list of functions might include:
- To maintain a water flow rate between 215 and 269 US gallons per minute
- To maintain a discharge pressure of 25.12 bar with the range of +17% to -10%
Step 3: Outline the ways the system could fail to fulfill its function
Functional failure is the failure of an asset, system, or process to fulfill one or more of its intended functions. While the asset may still operate in some form, it is classed as a failure if it does not contribute to operations as intended. Clearly outlining each of the potential points of failure for the system or asset using a method such as failure modes and effects analysis or FMEA provides the foundation for the remainder of the RCM process.
There are various ways to perform failure analysis so it is important to choose a methodology that is appropriate for your organization.
Example: For our centrifugal pump, the team may include the following failures related to the discharge pressure function:
- Unable to discharge water
- Discharge pressure drops below 22.61 bar
- Discharge pressure exceeds 29.4 bar
Step 4: Assess the impact of each potential failure
To fully understand what happens when a failure mode occurs requires wide-ranging and open-ended discussion of questions such as:
- What will be visually evident when the failure occurs?
- How will you be able to detect the failure?
- What impact does the failure have on the environment?
- What impact will the failure have on safety?
- What physical change will occur to the equipment?
- What changes may the failure cause to adjacent equipment?
- What alarms or notifications will occur?
To avoid going too broad, it helps to focus the questions at three different levels:
- What is the local effect on the individual component?
- What is the effect at the sub-system level?
- What effect will occur on the system?
Example: Our centrifugal pump identified impeller damage as one possible failure. Below is the breakdown of what the effects of that failure might trigger at different levels:
- Local effects of impeller damage: Pump vibration, a drop in pumping efficiency, or a reduction in suction power.
- Sub-system effects of impeller damage: Boiler low, boiler trip.
- Overall system effects of impeller damage: Reduced efficiency of the steam system, system trip.
Step 5: Plan a maintenance strategy for addressing each potential failure
The goal of an RCM plan is failure management rather than across-the-board prevention. Therefore, RDM plans distinguish failure management techniques that are proactive tasks versus those that are default actions.
Proactive tasks are maintenance actions taken before failure, to prevent it. This includes condition monitoring and predictive maintenance strategies but can sometimes result in unnecessary maintenance. In order to avoid that, RCM requires each proactive maintenance task to be technically feasible and worth doing. If it doesn’t meet these criteria, you should choose a default action.
Default actions are used when it is impossible to identify a proactive task that will be effective enough. Default actions focus on managing the failure itself and include:
- Equipment redesign
- Equipment modification
- Failure-finding initiatives
- Run-to-failure or reactive maintenance activities
Document your plan and include mitigation tasks for each potential failure identified in earlier steps, emphasizing preventive tasks for failures that have a more significant impact to your operations.
Example: In the previous step, we concluded that the centrifugal pump failure caused by the impeller being loose on the shaft has a high criticality. It has to be spotted and repaired as soon as possible.
Therefore, monitoring flows or vibrations as a part of a CBM or a predictive maintenance program may be a suitable solution. In both scenarios, you would be able to identify a developing trend, allowing scheduled maintenance/repair during planned shuts.
Step 6: Implement your maintenance strategy and optimize over time
Now that you have your maintenance plan, it will need to be implemented. How this step gets carried out will depend on the way your team manages maintenance. You may build your maintenance plan and tasks into your CMMS or ERP. Include training for applicable staff responsible for carrying it out.
Once implementing any new initiative, it is also critical to include plans to optmize it over time. Continue monitoring failure rates and output to determine the impact and effectiveness of your RCM program and so that you can refocus and improve it over time.
Requirements for implementing an RCM program
RCM is not an entry-level strategy. Ensure you have sufficient maintenance infrastructure, skills, and resources in place to execute the process. Over 60% of all RCM projects fail as a result of this lack of preparedness.
Organizational and maintenance maturity
Review your maintenance program and processes. If you have good history of running a preventive maintenance program and historical data to back it up, you are a good candidate for considering RCM.
In-house skills
Many organizations will hire consultants to help with RCM training and implementation. However, your maintenance and engineering staff still needs to have a good understanding of your equipment and operation.
Internal resources and team bandwidth
The RCM process will take time and tie up key staff from multiple departments. Inadequate resourcing is another key reason companies terminate RCM initiatives early, citing unexpectedly high resource requirements and project duration. By having the ability to divert bandwidth and resources to an RCM project is critical for its success.
Realistic budget expectations
Be prepared for your maintenance costs to increase. Nasa calls this the Implementation Bow-wave.
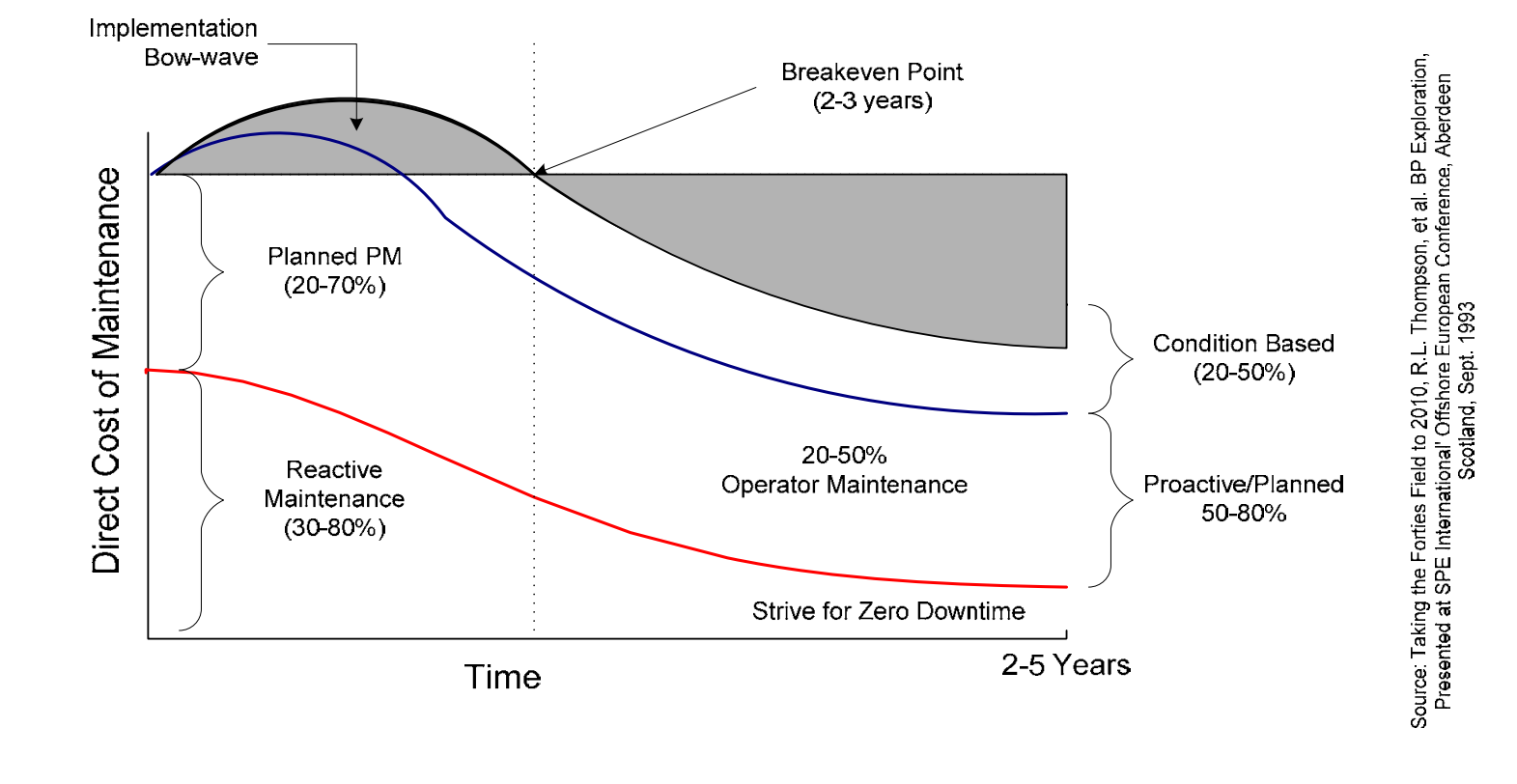 Graph that shows effects of implementing RCM on maintenance and repair costs. Source: NASA RCM guide
Graph that shows effects of implementing RCM on maintenance and repair costs. Source: NASA RCM guide
RCM requires extra expenses for training, technology, and equipment condition baselines. As more sophisticated testing occurs, you’ll find more faults, and your repair costs will increase temporarily.
In NASA’s case, this normalized after two to three years, after which savings began to grow. The costs continued to drop for the next five years.
Want to see Limble in action? Get started for free today!
Streamline your RCM process with a CMMS
Efficient RCM implementation requires considerable amounts of data and organization. A modern CMMS like Limble provides the data integrity and asset performance baseline to allow accurate comparisons to be made pre and post-RCM initiatives.
Schedule a demo or start a free trial to see Limble in action.


