If someone was trying to convince you not to start a predictive maintenance program, they might tell you that it is too complicated or expensive to implement. And while those might be valid concerns for some, the adoption of predictive maintenance strategies is only projected to grow.
If you are considering starting a predictive maintenance (PdM) program at your facility, this guide (or the video below), will show you all the steps you need to take to make it a success.
Is it hard to start a predictive maintenance program?
Implementing a PdM program is indeed more complicated compared to starting a preventive maintenance program. But the real level of difficulty will depend on the level of expertise available at your organization, the complexity of your assets, and the tools you have at your disposal.
The following sections will review the steps, tools, and expertise required to set up and maintain a PdM program. Once those pieces are in place, predictive maintenance becomes a much easier job, and one that is worth the return.
The Essential Guide to CMMS
The Essential Guide to CMMS

Steps for establishing a PdM program
Although the benefits of predictive maintenance are numerous, deployment can be challenging. So, before you start, it is important to have a well-defined plan covering the desired business outcome and project scope. Ideally, you should start small, learn and adjust as you go along, and use the insights gained for further expansion.
Let’s dive into step-by-step best practices for implementing a successful and sustainable PdM strategy.
Step 1: Identify assets for PdM
First, you must determine which assets to include in your predictive maintenance program. This distinction is important for two reasons:
- Not all assets deserve to be on a predictive maintenance plan because some won’t be cost effective. Certain assets that are largely expendable, can be placed on basic routine maintenance or allowed to run to failure.
- If this is your first tango with predictive maintenance, you don’t want to complicate things from the start. It is better to focus on a few selected assets and run this as a pilot project.
By checking historical machine records – maybe over a two or three-year period – you can identify the assets that are most vital for your business processes and would cause a substantial disruption if they unexpectedly failed.
Some organizations go through a thorough criticality analysis on their assets for this step. Another quick way to identify such assets is to note:
- Assets that demand the most financial and human resources
- Assets with high repair/replacement costs that also record frequent breakdown incidents
- Equipment which, if it breaks down, limits or halts production or service delivery
- Assets that do not directly impact production, but the repair costs are considerable and/or take longer to complete
- Machines that are so sensitive or complex that they require “specialist” attention to get them back online (which often comes along with a big invoice)
Assets that meet the above criteria are the best candidates for the PdM program.
Step 2: Collect and log actionable data
Machine records present a valuable and time-saving source of actionable data to help get PdM rolling. Such data offers information about machine behavior that will, to a large extent, determine how you design the PdM model.

Sources of historical machine data include:
Manufacturer’s information
New equipment always comes from the OEM with comprehensive manuals and instructions. This information covers essential details such as:
- What kind of maintenance is required
- How often it should be done
- How to perform it safely
Manufacturers’ instructions form the basis for starting a maintenance plan on each asset.
In-house historical data collection
Companies that have been keeping accurate maintenance records can quickly gather historical data for each piece of equipment. Machine data can be extracted from:
- Hard copy maintenance records and charts
- Your CMMS software
- Software from other departments (e.g., procurement and accounting).
For instance, this is how an asset report may look in a Computerized Maintenance Management System (CMMS):
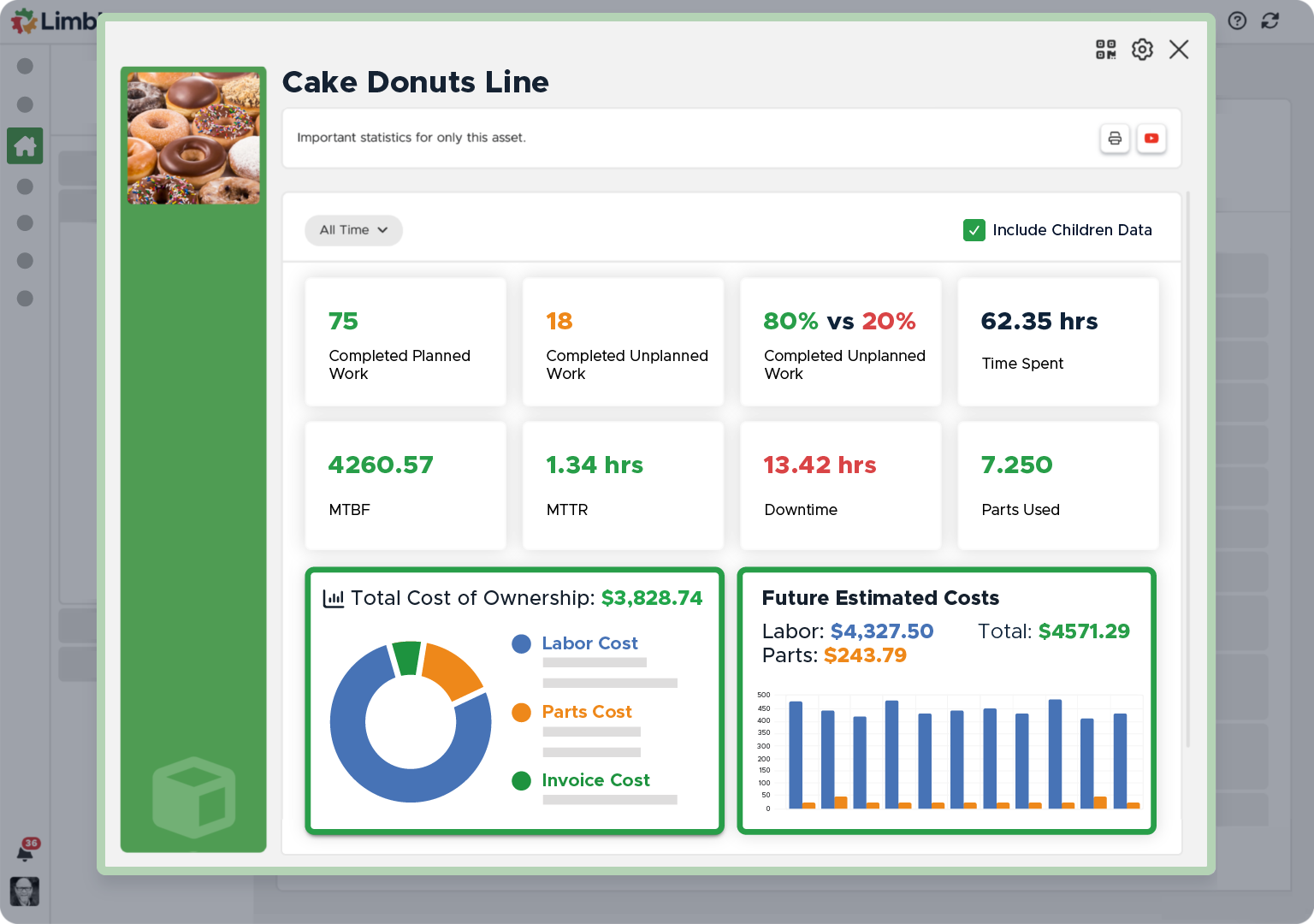
Metrics like total costs, future estimated costs, and MTBF show how often an asset fails and will help you determine if an asset is worth putting on a predictive maintenance plan.
Leverage staff expertise
You can get valuable information that may not be available in writing by involving the staff that work with the machines daily, like maintenance technicians and machine operators.
They already have a working knowledge of each asset and are familiar with many failure patterns. Their input will make it easier to pinpoint the specific problems they face with each asset and how the eventual predictive model can help.
Step 3: Analyze failures
The goal of this analysis is to identify failure modes and patterns of the assets in your PdM program. It is important to focus on establishing the following:
- Severity (and effect) of machine failure
- The frequency of failure
- The difficulty of identifying the failure
One of the most accurate methods for completing this step is Failure Mode and Effects Analysis (FMEA). Failure modes are the different events or ways in which an asset can fail. FMEA is a product or process reliability analysis tool used to identify failures affecting a system, prioritize corrective actions, and limit failures overall.
FMEA is a very detailed and thorough process that involves several worksheets and calculations, but the overall process includes the following steps:
- List the normal functions of the assets in your plan
- Consider all potential failures for each asset
- Identify the effect of each failure on the asset itself, and on the people, processes, and systems that rely on it
- Rank the severity of each failure (usually from 1 to 10)
- Determine the occurrence of each failure mode
- Assign a ranking for ease of detecting each failure
- Use those rankings to calculate the risk priority number (RPN) for each failure.
- Assign actions to the failures with the highest RPN
- Review and re-rank RPNs as failures decline over time
The result is a prioritized list that guides development of failure predictions for the highest risk assets first.
Step 4: Choose and implement condition monitoring techniques and equipment
Predictive maintenance programs integrate different types of machine information such as performance data, maintenance history, and design data to make timely decisions about maintenance intervention. Gathering all this data requires specific technologies that enable condition-based monitoring.
Condition-based monitoring is a crucial step in PdM planning process. The goal is to preempt asset failures by placing monitoring sensors on the assets. The sensors collect data and share it with connected systems that analyze it and use it to identify patterns that can be applied to predict future failures and inform your maintenance actions.
A wide variety of sensors are available, including (but not limited to):
- Thermometers
- Tachometers
- Endoscopes
- Thermal cameras
- Leak detectors
- Accelerometers

The most common condition monitoring techniques used to detect these faults are:
- Vibration analysis
- Lubricant analysis
- Infrared thermography
- Ultrasound testing
- Dynamic pressure analysis
- Acoustics testing
- Current and voltage testing
Identifying failure modes for your critical assets helps you to choose the appropriate monitoring technique or NDT test for each asset.
For example, vibration analysis is the most commonly used technique for rotating equipment as it can detect the faults that this category of equipment is prone to, such as roller bearing wear, mechanical looseness, gearbox wear, shaft misalignment, and unbalance.
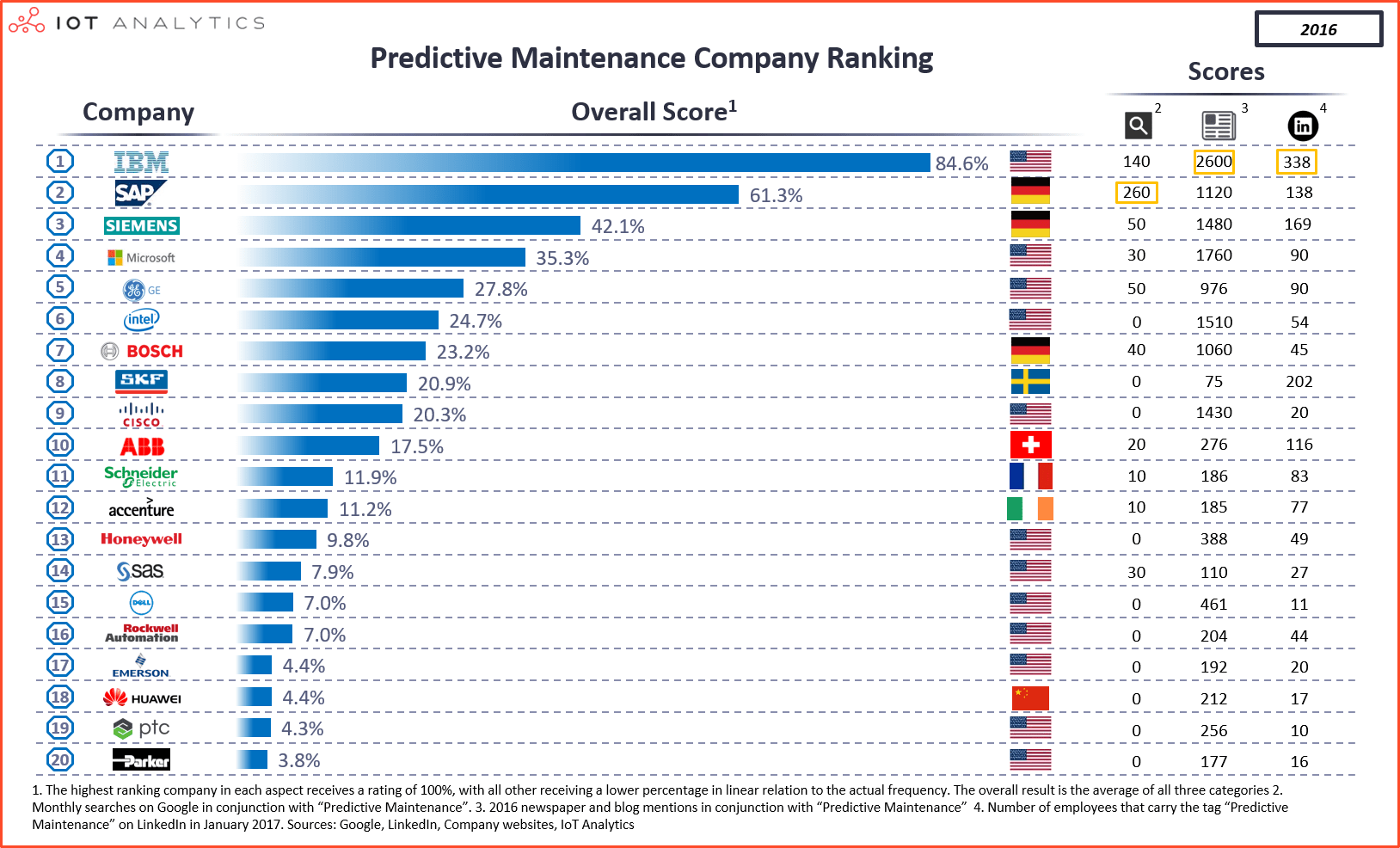
There are several reputable brands of sensors you could choose, manufactured by companies like Siemens AG, Schneider Electric, Bosch GmbH, ABB, Honeywell, to mention a few.
Step 5: Develop algorithms for making failure predictions
Next is identifying equipment failure patterns and using them to create algorithms that can predict the failures in your FMEA. This is the core of predictive maintenance, and what happens here will get you the equipment monitoring alerts you need.
The predictive system uses both the information coming from condition monitoring sensors and prognostics algorithms to analyze machine data. Let’s take a brief look at how both functions interact:
Condition monitoring
The data derived from condition monitoring sensors track any behavior changes that may indicate deterioration. It does this by tracking unusual sensor readings to detect faults by comparing sensor data against readings that are considered normal.
Prognostics algorithms
Prognostics algorithms are used to estimate the remaining time-to-failure (RTTF) or the remaining useful life (RUL) of a machine or component. They help forecast failures by comparing the condition of a machine over time. These algorithms can be established using either modeling or machine learning technology, or by combining both.
Predictive modeling is initially done by a data scientist who creates predictive models. Then, a machine learning technology is used to update algorithms over time based on sensor data, increasing its predictive capabilities with each asset failure incident until unplanned downtime can almost be eliminated.
Although this process may take a while to perfect, the final result is an automated system that calculates the RTTF, generates alerts when machine conditions deviate from established thresholds, and determines when maintenance intervention should happen.
Step 6: Deploy to pilot equipment
The final step of implementation is to deploy the technology by integrating it into a few selected pilot assets.
When implementing this technology, it is important to consider whether or not to use local condition monitoring sensors (sensors attached directly to machines) versus cloud-connected devices (sensors that wirelessly connect to a software platform that has the capacity to store large amounts of data). The latter option will provide the capacity for a lot more data which will be necessary as you add more and more assets to your PdM program.
The analysis generated using cloud-based software can then trigger notifications for maintenance based on your preferences.
Checklist for Creating a Preventive Maintenance Plan
Following a consistent Preventive Maintenance Plan can make life easier. Use this checklist to create your own!

Is your facility ready for a predictive maintenance program?
While PdM represents a compelling proactive approach to maintenance, it does have a barrier to entry.
Let’s review the requirements you should have in place if you are serious about implementing a predictive maintenance program:
Upper management support
Starting a predictive maintenance program is a big step forward for any facility and is not a project you want to run without having strong support from upper management. You will need funding, help from other departments, and possibly even a third-party consultant. You don’t want to be left stranded in the middle of the implementation process.
Setting up a pilot project and laying down realistic expectations can go a long way toward getting the necessary approval from the people in charge.
Appropriate funding
Having a flexible budget to invest in technology and expertise is a big bonus, as you will need to:
- Buy sensor monitoring equipment
- Invest in a CMMS or other specialized software
- Possibly hire external data scientists to help with creating predictive models
- Spend resources on training technicians
The right condition monitoring equipment
The real power of predictive maintenance hides behind two simple concepts:
- The ability to monitor the condition of your assets in real-time
- Feeding that data into complex algorithms that allow you to schedule necessary repairs and replacements correctly
Without appropriate condition-monitoring equipment, the algorithms won’t have enough data to do their job correctly and give you accurate predictions and alerts.
Access to the right software and analytics
Arguably the most important requirement for PdM is ensuring you have the right platform for storing and analyzing machine data. It is not rare that businesses look for outside help with this part of the process.
A CMMS is crucial to creating and running your PdM program by helping you schedule and oversee all maintenance activities – from ensuring you have the necessary spare parts when you need them to tracking task progress and maintenance costs.
More advanced CMMS solutions can even be configured to automatically create tasks depending on the incoming sensor data. In addition, some organizations might also need to look into employing advanced predictive analytics that will help them with the creation of necessary predictive models.
Training requirements
While a lot of condition monitoring sensors can be connected to software like a CMMS, some CM equipment might need manual input and monitoring from your maintenance teams who need to know how to use it.
Additionally, no matter which maintenance strategy you’ve been using, a move towards predictive maintenance will require some workflow changes and shifts for the scope of the whole maintenance department.
This is yet another reason why starting with a pilot project is a good idea – it gives everyone enough time to get familiar with all of the necessary changes.
A switch to predictive maintenance
Managers often like to wait for the right time to switch to predictive maintenance, which is understandable, considering it can be a big project. But if you’re on top of most of the requirements necessary to begin a PdM program, you should be able to begin a pilot project and work on addressing what you’re missing as you go. And the sooner you start, the sooner you begin to reap the benefits of predictive maintenance.

thanks for your extremely nice software
Thank you for your kind words! 🙂
Comments are closed.