In an ideal world, all assets would be designed in such a way that they rarely fail and that they are easy and cheap to maintain. Since we do not live in a fairytale, we rely on Reliability, Availability, and Maintainability analysis to find a balance between asset productivity, purchasing, and maintenance cost.
Explaining the concept of RAM and how it is applied takes more than a single paragraph. Dig into the text below if you want to learn more.
What is Reliability, Availability and Maintainability (RAM)?
Reliability, Availability, and Maintainability (RAM) are design attributes of a system or an asset. They hold great importance, not just to system engineers, but to operators and maintenance professionals as well.
Collectively, these parameters are leveraged to improve the productivity of the asset over its life cycle by reducing waste, maximizing profit, and ultimately, optimizing its overall life cycle (LCC) costs.
Let’s quickly define each parameter to ensure we are on the same page.

Defining reliability
The term Reliability represents the probability that an asset will operate without failure in a given time under strict conditions. It is commonly calculated through metrics such as Mean Time Between Failures (MTBF) for repairable items and Mean Time to Failure (MTTF) for non-repairable items.
Defining maintainability
The term maintainability describes how easy and resource-intensive it is to perform maintenance on an asset. It can also be used to define the probability of an asset returning to its intended state upon completion of a maintenance task. It is commonly measured by a metric called Mean Time to Repair (MTTR).
Defining availability
Availability is a unique parameter that combines both reliability and maintainability parameters. It provides the probability that an asset is in operable condition at a given time (it is not undergoing maintenance or repairs).
Checklist for Creating a Preventive Maintenance Plan
Following a consistent Preventive Maintenance Plan can make life easier. Use this checklist to create your own!

Why are these parameters studied together?
Reliability, Availability, and Maintainability have to be studied together (a process called RAM analysis) to reach a meaningful and actionable conclusion. This is because these parameters are interdependent and often in conflict with each other. In other words, improving one parameter will likely result in the deterioration of the other two.
Let’s introduce an example.
Machine design can be made very efficient by incorporating complicated fault tolerance mechanisms, which can improve its inherent reliability. However, complicating the design can proportionally increase the time maintenance technicians have to spend on routine maintenance, reducing its maintainability.
We can easily flip this into an opposing direction.
The maintenance instructions can be made overly simple. For instance, you can increase maintainability by reducing the number of items to sign off on your preventive maintenance checklists. However, this will likely result in some parts of the machine not being properly inspected, increasing the probability of failure and decreasing its reliability.
Some industries have tight requirements for minimum Levels of Service (LOS) – defined under the definition of availability – that have to be maintained under all conditions. This means the reliability and maintainability parameters have to be analyzed keeping in view the consideration of the availability.
The application of RAM analysis throughout the equipment life cycle
RAM analysis is generally performed at the design stage by a team composed of design, systems, and reliability engineers. However, the analysis can be repeated throughout the lifecycle of the asset by maintenance and service reliability engineers that have key data points on asset health and performance.
The Reliability, Availability, and Maintainability analysis can be expanded by adding the safety component to existing parameters, turning RAM into the so-called RAMS analysis.
RAM analysis after the design stage can be helpful to evaluate the current state of the asset. After all, assets rarely operate in ideal conditions. You could say that each asset has a unique lived experience.
No two assets are the same
Two identical assets installed into different operating environments may perform differently and have very different lengths of useful lives. This difference could be due to a range of factors such as:
- Extreme weather/operating conditions that can cause accelerated degradations
- Manufacturing deviations
- Diversity in training and competency of staff operating and maintaining the equipment
- The quality of spare parts used
- …
All of this leads us to the conclusion that assets will have varying failure rates. Therefore, the purpose of extending RAM analysis during the operations phase is to account for the effect of changing conditions and the associated failure rates.
To understand this concept better, consider the example of a railway station where every locomotive has to arrive and depart in a precise 3 min window to achieve a desired on-time performance of 95%. In that context, the maintainability of the train locomotive has to be decided in such a way that it is sufficient to cater to the failure rates for each sub-system of the locomotive.
Now, if the maintenance level decided during the design stage is kept constant throughout its useful life, it will likely result in over or under maintenance of the locomotive at different stages of its life cycle.
Maintenance levels should match the asset’s needs
Let’s continue with the locomotive example.
During infant mortality when the failure rate is decreasing, the maintenance or inspection levels may not be sufficient to keep the locomotive in prime operating condition. Similarly, during the wear-out zone, when the failure rate starts to rise again, the maintenance levels may again shortfall. In other words, maintenance levels cannot be kept constant from equipment installation to disposal.
Ideally, you would have information on the asset health recorded in your CMMS software. You could then use that info to determine the actual failure rates of the asset. The actual maintenance level could be adjusted corresponding to those failure rates while taking into account the desired trade-off between reliability, maintainability, and availability.
Supporting RAM with condition monitoring
Often industries incorporate advanced condition monitoring systems that provide real-time data about the health of the asset and inform equipment operators about the onset of potential failures before they turn into actual functional failures.
Asset condition monitoring is a well-known and proven technique for reducing the P-F interval of the asset. It directly increases maintainability and availability metrics.
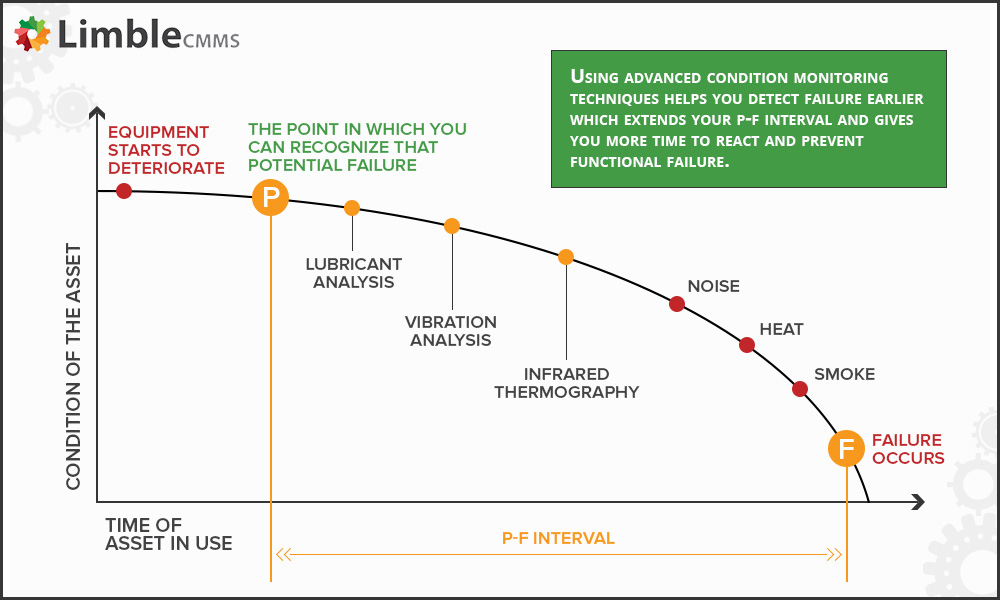
Maintainability is improved in the sense that there will be less need to disengage the equipment from the production line to visually inspect specific parts. Similarly, availability will be improved as unnecessary downtime will be curtailed and will occur only when the equipment is nearing its potential failure point in the P-F interval.
This data provided by condition monitoring technology can also be used by system engineers to proactively improve equipment reliability through design changes.
In general, this phenomenon of continuous improvement has been seen to improve reliability, availability, and maintainability at each stage of the asset lifecycle.
Min-maxing costs and benefits
Due to the ever-rising cost of material, business competition, soaring inflation, and shortage of supplies and manpower, it has now become an expectation from system engineers to develop systems that do not just operate but actually function optimally – minimizing operating and maintenance costs, while maximizing overall benefits.
To achieve this, the right strategy is the one that adjusts the maintenance of the asset and its renewal/replacement strategy in a way that optimizes the overall life cycle cost of the asset.
The only way to do that is to have the right data and analyze it in the proper context. Contact us today to get more info on how Limble ensures you always have quick access to condition monitoring data and historical maintenance information.
