As we become more reliant on hardware and software, high reliability is becoming a necessity for an increasing number of systems. Over the years, various methodologies have been developed in an effort to improve reliability and maintenance processes.
We will explain one of those today.
Join us as we discuss what hides behind the FRACAS acronym, what the process looks like, and how to successfully implement it into your organization.
What is FRACAS?
A failure reporting, analysis, and corrective action system (FRACAS) is a framework that provides a disciplined and iterative method for solving reliability and maintenance issues throughout the life cycle of a system. It is an important part of many reliability programs.
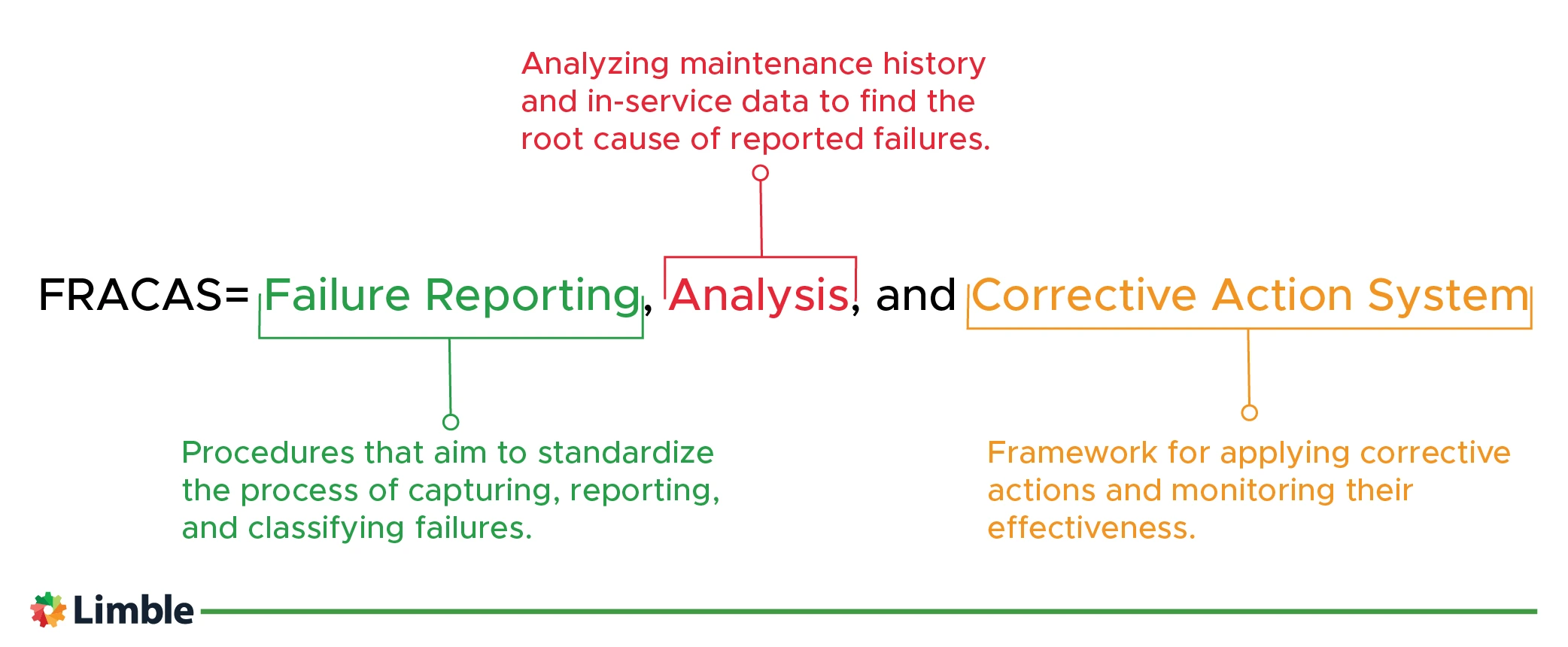
The US defense department developed the FRACAS process back in the 1970s, publishing MIL-STD-2155 in the mid-1980s, and finally MIL-HDBK-2155 in the mid-1990s, with the title, Failure Reporting and Corrective Action Taken.
Despite its military roots, FRACAS can be applied in any industry.
What is the purpose and applicability of FRACAS?
The FRACAS process is a business-wide methodology. It usually uses CMMS software to capture a failure event in a standardized format, allowing engineering and maintenance personnel to classify and analyze it, develop actions to prevent its reoccurrence, and monitor whether the action has been successful.
At first sight, it can be challenging to tell the difference between FRACAS and FMECA. Reliability engineers will tell you that FMECA is considerably more abstract and conceptual, and it’s more often used at the design stage.
In contrast, FRACAS is an operational process used across the entire system lifecycle. It immediately follows an in-service failure with the goal of preventing the same thing from happening in the future.
There are no templates you can copy and paste when implementing a FRACAS system. As the methodology is generic, each business must do the work required to implement a FRACAS system aligned with and pertinent to its operating situation.
However, that doesn’t mean it is not worth looking at a few examples. There are some industry-specific FRACAS programs out there you can use as a guide. One of the best known is ISO 14224:2016, used within the petroleum, petrochemical, and natural gas industries to standardize failure data collection and failure modes.
Implementing FRACAS comes with significant benefits
What are the benefits of implementing FRACAS? It is like asking what the benefits of a smoothly functioning reliability system are. They include:
- A decrease in the total cost of ownership/lifecycle costs. When a production system suffers fewer breakdowns, you can save an extraordinary amount of money. You will spend fewer spares, save on labor costs, and extend the useful life of your equipment.
- An increase in asset availability. Greater operational availability supports increased revenue by creating more capacity for new clients. It also increases product margin by amortizing equipment costs over greater product quantities. In translation, it decreases production cost per unit.
- An increase in customer satisfaction. Improved equipment reliability ensures that planned quantities, quality, and delivery dates are respected, ensuring client satisfaction and retention.
- Better regulatory compliance. Equipment failure threatens employee safety and can lead to environmental non-compliance. Operating in a controlled environment allows for planned shutdowns and stoppages rather than rushed emergency responses to failure.
- A reduction in scrap rates and warranty claims. Equipment failures or degradation can produce products that are out of specification or exhibit high failure rates. Improved reliability reduces the impact and occurrence of such events, lowering rework costs and improving client satisfaction.
With that out of the way, it’s time to check how failure reporting, analysis, and corrective action system looks in action.
A typical FRACAS process following a failure
Working with an established FRACAS methodology does not appear outwardly different from the informal troubleshooting and rectification that normally occurs following an important failure.
The difference lies in its transparency, rigor, and standardization. This closed-loop process works completely through an issue and institutes formal actions before monitoring the outcomes for effectiveness.
Let’s imagine an example we will use throughout the steps below.
Assume you have a defined part of your production line that begins producing a non-conforming product. A line stoppage occurs as technicians troubleshoot and rectify the problem by replacing several hydraulic rams. The result of the fault is hours of downtime, products requiring scrap or rework, emergency callouts of maintenance personnel, and a production backlog impacting batch delivery.
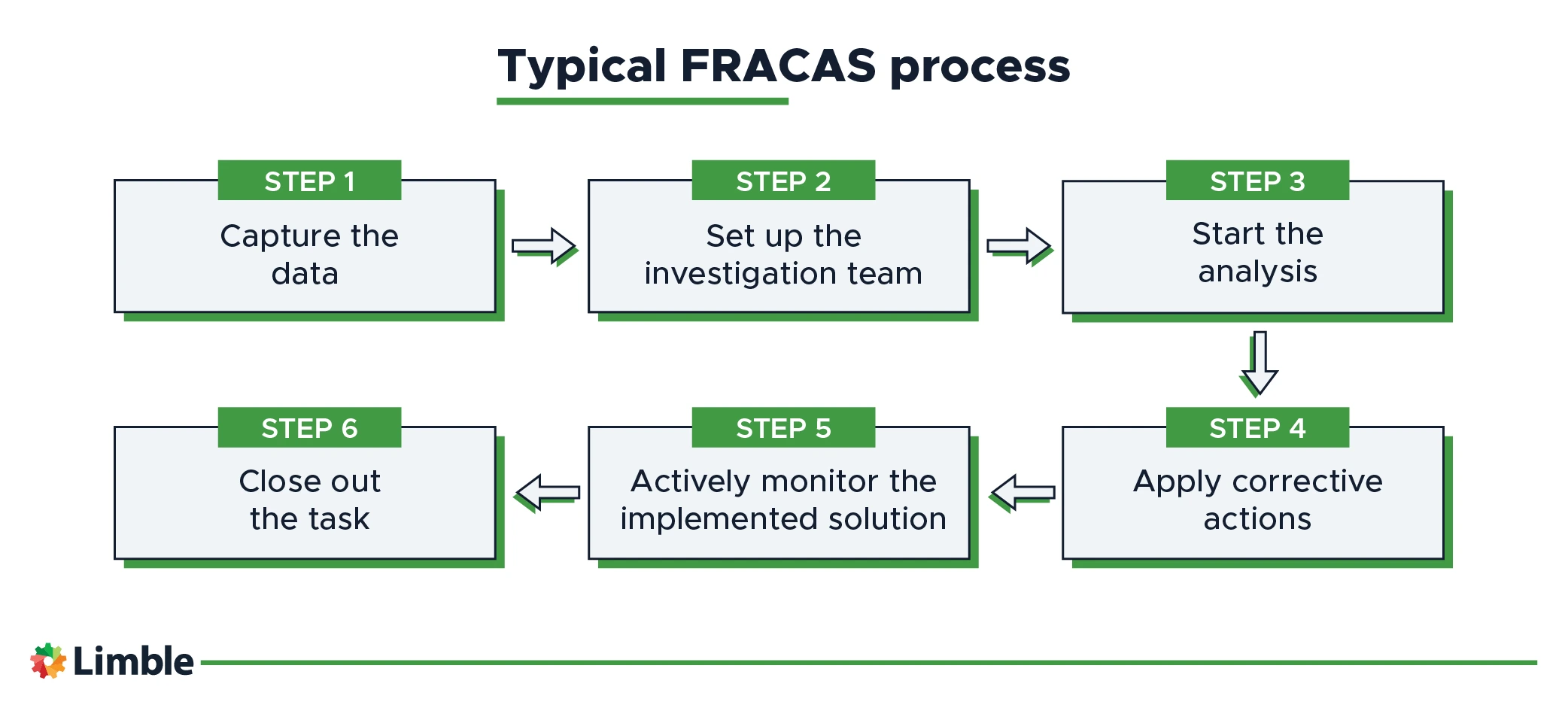
Step #1: Capture the data
The first step of a typical FRACAS procedure is the capture of data. In this case, our CMMS requires operators and maintenance technicians to answer various standardized questions like:
- When did the operator first recognize the fault?
- Who noticed it?
- What were the effects of the failure?
- When was the fault-finding completed?
- What were the actions taken?
- Which components were replaced?
The data may also include the consequential impacts arising from the failure, including cost, downtime, inventory use, and quality impacts.
Step #2: Set up the investigation team
The impact of the fault triggers predetermined criteria that call for further analysis. An individual from engineering and maintenance is assigned the fault for a detailed investigation and root-cause analysis. Let’s call him Mark.
Most FRACAS processes use a matrix to define who is responsible, accountable, consulted, and informed on the issue’s progress. This matrix is known as a RACI chart (more on this a bit later).
In this case, Mark must keep all relevant parties in the loop on the investigation, as outlined in the aforementioned chart.
Step #3: Start the analysis
Detailed analysis may require a team to be selected or access to expert knowledge from within the company or from suppliers and OEMs.
In the case of our hydraulic rams, Mark begins the investigation by reviewing the CMMS data on the replacement, mean-time-between-failure (MTBF), and in-service breakdown of the component.
History shows an inconsistent failure rate, with no reliable data to establish the in-service component MTBF. Mark requests a bench test and strip of the rams, which reveals cylinder rod drift, indicating excessive leakage past the piston seals.
Following that revelation, Mark asks the contractor that overhauled their cylinders to review their strip and repair data. The contractor cross-references ram serial numbers with their failure rates and overhaul records. It seems that, where low MTBF occurs, the contractor used a piston seal from a specific manufacturer in the last overhaul.
The contractor uses various seal manufacturers to supply the part, with all seals conforming to the required specification. However, the seals from one manufacturer consistently link to reduced service life.
Step #4: Apply corrective actions
Mark reports their findings to the quality department. They formally advise the contractor not to use the suspect seals in further servicing. The company also quarantines any rams in inventory serviced with the suspect o-rings until the contractor can replace them.
The results of the investigation and agreed actions are communicated to all relevant parties.
Step #5: Actively monitor the implemented solution
Over the ensuing 12 months, Mark and his team use their CMMS to track and report on the rams’ reliability. The actions they took have been successful. The MTBF has stabilized within a reliable range, allowing the generation of a cycle-limited preventative maintenance task that removes the rams for overhaul before failure.
Step #6. Close out the task
At each step of the process, all data was recorded in a prescribed format to allow subsequent review and analysis. Estimates of the improved reliability are combined with a financial analysis to close out the FRACAS task before archiving within the CMMS.
And Mark can finally relax.
The Essential Guide to CMMS
The Essential Guide to CMMS

Steps for implementing FRACAS in your business
The following steps provide a roadmap for implementing a FRACAS methodology.
Remember, you must customize the final system to your industry, equipment, and way of working. Copying the system of another business will be sub-optimal and possibly doomed to fail.
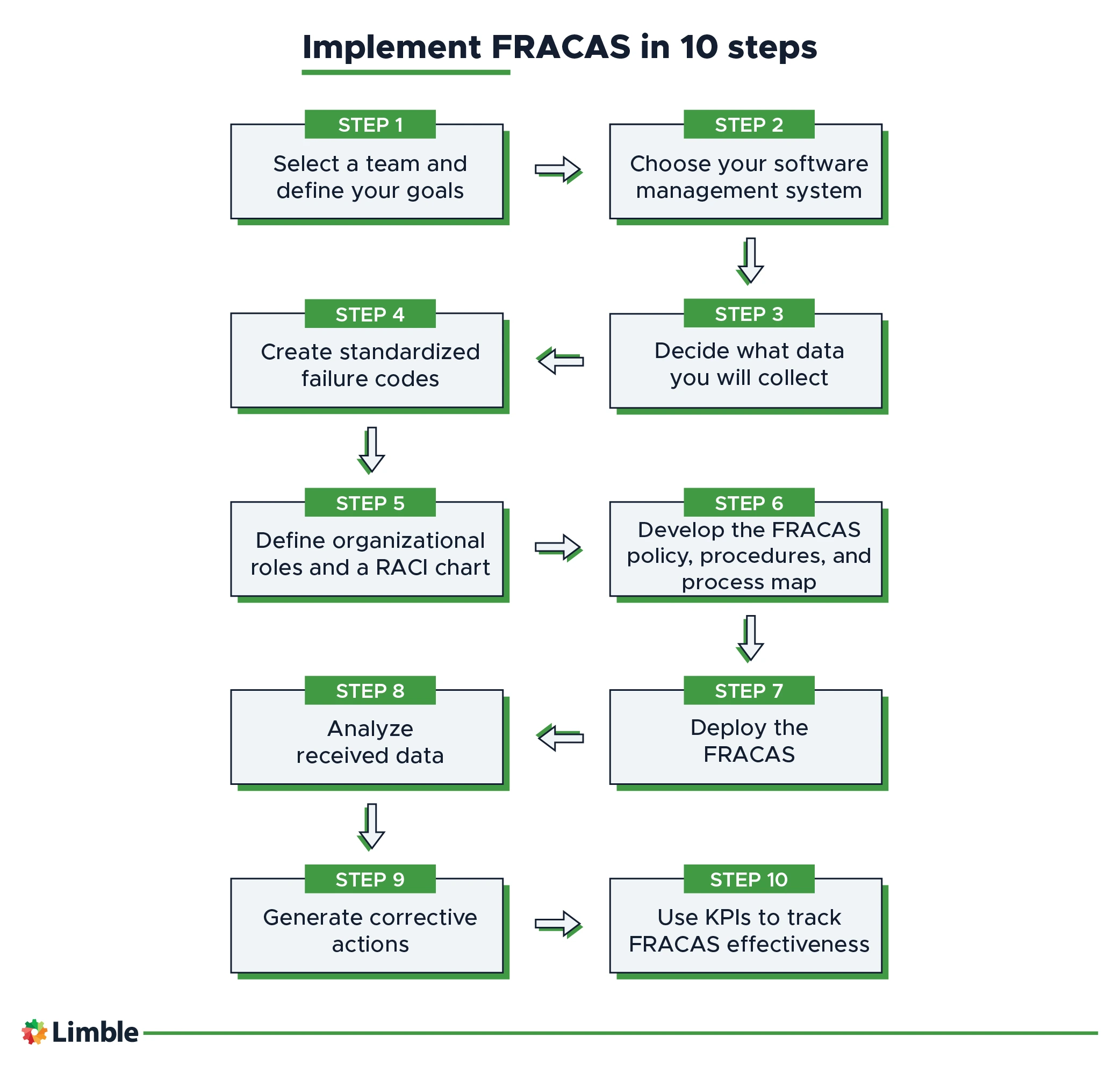
1. Select a team and define your goals
A FRACAS system is at the core of your reliability program. However, this doesn’t mean that having technical personnel is enough.
Ideally, you will be able to pull people from the following departments:
- Maintenance and reliability engineers for obvious reasons.
- Someone from the quality department to help structure the methodology and align it to the company standards.
- Someone from the warehouse, as FRACAS will inevitably impact them, and you’ll need their buy-in and support.
- The equipment operators will be key to making your new system work, so possibly include someone from production.
- Senior management should also be involved to help clear the inevitable roadblocks and make judgment calls on strategy.
As a team, spend time aligning and agreeing on the goals for the new system. It’s easy to become sidetracked by data collection. Keep in mind that your role, and that of the system you devise, is to improve reliability. Agree on and document what you hope to achieve.
2. Choose your software management system
While you can run a FRACAS system manually, it makes no sense in this day of technology. You will want to use a CMMS or EAM. Both allow real-time data collection, analysis, and reporting and provide a readily accessible archive of in-service history.
Designing and building your FRACAS workflow with the management system in mind is an efficient way to integrate your data capture, storage, and analysis requirements.
3. Decide what data you will collect
Avoid becoming bogged down in too much data. Use the information that enables making decisions and taking action. Your data may include failure modes and mechanisms, historical data, reliability information, MTBF, or mean time to failure (MTTF). You’ll certainly need product specifications. If you already use CMMS, much of what you need will be at your fingertips.
To ensure a rigorous and auditable process, create a table showing what data you need to collect and why. Identify how it will be collected and the tools you’ll use to analyze it.
When you first implement a FRACAS, start small. Your data may be as simple as the number of failures by component, system, or area.
4. Create standardized failure codes
A core principle of FRACAS is using a standardized taxonomy for failures for easier analysis. How would you sort and sift to aggregate the data if everyone wrote long-hand faults?
The aviation world does this well with its ATA codes which describe every system and subsystem on an aircraft and then extends to zones. For example, when using this system to search for failures in the landing gear steering, you’ll use 32-50 as the search criteria. The landing gear is ATA chapter 32, while the steering subsystem is 50.
Devise similar codes to suit your organizational context. All employees can use them to report failures and rectification efforts. You can even apply standard codes to failure modes for greater specificity.
Your CMMS is an excellent tool for enforcing this discipline by preventing the entry of any codes that do not adhere to the approved structure.
5. Define organizational roles and a RACI chart
Defining clear role responsibilities in new initiatives is crucial. Create a RACI chart with FRACAS tasks listed down the Y-axis and relevant roles along the X-axis.
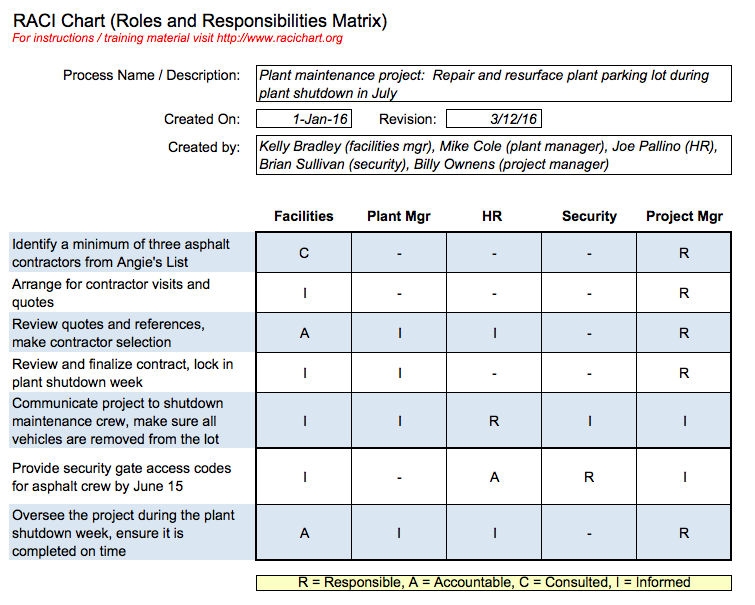
Example of a RACI chart used for a parking lot repaving project. Source: RACI Charts
At each intersection of a task and a role, decide whether that role is responsible for executing the task (R), accountable for its execution (A), consulted with (C), or simply informed (I). If the role has no involvement, place a horizontal line (-).
By using this chart, everyone can see who collects data, who does the analysis, and who is responsible for implementing corrective actions.
6. Develop the FRACAS policy, procedures, and process map
For those that dislike administration, this will be the least enjoyable part of the process. Unfortunately, this step is vital to ensure everyone is clear on what FRACAS is, why it is used, and how the system works.
Your FRACAS policy should include:
- The organizational roles
- A RACI chart that features key data required, the report formats, and the training each role should receive
- A process map that outlines the required steps and procedures.
7. Deploy the FRACAS
Distribute the policies and procedures manual and begin training the involved personnel while holding information sessions to update all employees on the new system. Data collection and analysis can commence.
8. Analyze received data
In the analysis phase, you will use your preferred tools. However, the intent is to reach the root cause of the failure to inform corrective actions. The data can be sorted into predominant failures using basic Pareto analysis, with common failure causes identified using Weibull analysis.
Standard root cause analysis techniques like Five Whys, Fish-bone Analysis, or an Ishikawa diagram can help drill down to actionable causes.
9. Generate corrective actions
Actions used to address failures can take many forms. You may work with a supplier or an OEM to modify equipment, change operating processes, or use alternative components to prevent future failures. There might be inspection tasks, condition monitoring, or life limits on components that reduce the impact of future problems.
Regardless, during the generation of corrective actions, it is important to remain focused on preventing the analyzed failure, achieving business goals, and not creating consequential impacts that shift the problem elsewhere.
10. Use KPIs to track FRACAS effectiveness
FRACAS is a closed-loop system that works on the principles of continuous improvement. The only way to close the loop after implementing corrective actions is to monitor the effectiveness of the outcomes.
Action monitoring aside, it is also wise to implement KPIs to monitor if the FRACAS system is being used and if corrective actions are properly implemented. Try to develop a few indicators that you can roll into a dashboard, providing a summary of the health and effectiveness of your FRACAS system.
Quick tips for avoiding common mistakes
Complex methodologies always have multiple points of failure. Follow the tips given below to avoid common mistakes when implementing and operating a FRACAS system.
Don’t use maintenance tasks as a default corrective action
Adding more and more maintenance tasks as a default method of preventing failures bloats your maintenance program. It adds cost and complexity, reducing its overall efficiency.
For instance, in a safety plan, using personal protective equipment (PPE) should be the last recourse for preventing an injury. Similarly, maintenance tasks should be the last recourse in a FRACAS process.
The superior solution is to eliminate the problem through design modification, new equipment, or production process changes.
Don’t over-collect data
The overcollection of data is insidious in FRACAS, with many believing that more data is better. Try to target your data collection by narrowing it down to the highest priority issues and using data to monitor those concerns specifically.
Too much data overloads a FRACAS, making meaningful results more difficult to achieve.
Leverage the power of a CMMS
Your CMMS is the central repository of your maintenance data and in-service history. It makes no sense to use a parallel system or implement a manual FRACAS that requires a human to manage the interface.
A CMMS has the in-built functionality to automate much of the FRACAS process, including data analysis, dashboard creation, and failure alerts once a threshold is triggered.
Make the system easy to use
You can standardize and digitize as much as you like, but your employees will need a role in the process sooner or later. Keep it simple, as making the process arduous or convoluted will cause people to cut corners or fail to use the system as designed.
As with any new system, it will be successful if it removes burdens from employees, not adds them.
Share successes
Create a virtuous circle using constant feedback and updates on the gains and successes experienced due to the FRACAS system. Reinforcing its value and maintaining its visibility among employees will embed its usefulness into the organization, maintaining support for the initiative.
The path to the peaks of reliability
A well-designed and rigidly implemented FRACAS forms the core component of a robust reliability system, returning margin to profits, increasing client satisfaction, lowering costs, and driving efficiency.
To support your journey to higher reliability, take Limble CMMS with you. It will keep you safe and have your back by providing the necessary data and keeping your team on the same page. Oh, and you can also use it to organize and streamline all of your maintenance management efforts.
To learn more about Limble, get in touch with our support team or schedule a product demo.
