Everything breaks eventually. When rebooting doesn’t solve the problem, we brainstorm causes and test them to find the issue. That is troubleshooting in a nutshell.
This article will cover what troubleshooting is, some common troubleshooting scenarios, and ways to streamline the process using your CMMS (computerized maintenance management system).
What is troubleshooting?
Troubleshooting is a step-by-step approach to finding the root cause of an issue and deciding the best way to fix it to get it back in operation. Troubleshooting is not just for equipment that has completely broken down. We also use it when a machine is just not working as expected. Efficient troubleshooting is an essential part of asset management, diagnosis, and repair.
Machines that are properly operated and routinely maintained are less likely to suffer major breakdowns. Still, there will never be a zero chance of failure. If you are using equipment, it will, at some point, need repairing.
When and why to troubleshoot?
It may seem obvious that troubleshooting occurs whenever there is any kind of, well, trouble. But anticipating the different types of problems that may arise can help you streamline your response. Broadly speaking, troubleshooting is done in the following instances:

1) Device failure
This is the big one: the most urgent reason to troubleshoot. The machine is broken, entirely out of commission, and needs to be fixed pronto to keep working. This can have a knock-on effect in a company by bringing all operations to a grinding halt and putting everything on hold.
The fact is, unplanned downtime is expensive for companies, often costing them hundreds of thousands of dollars per minute. Suppose you’ve got a capable maintenance team that knows how to troubleshoot effectively. In that case, you can reduce high-severity outages and save the company money.
Utilizing a modern CMMS like Limble for troubleshooting checklists can help reduce downtime. As an added bonus, each member of your team becomes more valuable to you when they have experience troubleshooting efficiently and effectively.
2) Unexpected operation
Every machine has a defined set of functions it can perform. Most devices don’t do things exactly the same way every time because of limitations in engineering and human error (as hard as we may try to avoid it). Even with these slight variations in performance, the machine can operate smoothly. This is considered its normal operation range.
If the machine starts to run outside these ranges, we may have a problem, and it needs to be on your crew’s radar. These situations are not as urgent as a total failure. Still, unexpected operations should be reported to fix the problem before a real issue comes up.
Take the cooling fans in your plant, for example. Imagine they are running and pushing out cool air, but every so often, they stop blowing for a few minutes (or the air isn’t as cold as it should be). Other equipment might overheat because of that malfunction and eventually start to break down. Fixing the fan as soon as you know about it will save the company time and a lot of money.
Getting operational users to log faults when they come up can be a great way to get to the problems early and avoid total failure. Using your CMMS to log the problem will give you a written history of what happened and how it was fixed, making troubleshooting time in the future that much easier.
3) Other anomalies
The machine is working within the ideal operating range and is delivering the expected output. However, an operator has spotted some anomaly. It could be a strange sound, a weird smell, visible smoke, excessive vibration, etc. Such anomalies should also be investigated within an appropriate time window
[limblequote]The process for reporting problems should never be made into a tedious task. It is the only way to ensure people use it. Limble users can email, phone, scan a QR code or log a fault in person. The system even has a central account that will transform emails into work requests and creates a central hub where history can be recorded and referred to later.[/limblequote]

With detailed asset history logs and troubleshooting experience, users can take care of things independently. This will free up more time for your team to focus on things that matter more.
What are the benefits of troubleshooting?
There are a lot of costs that come with reactive maintenance and a lack of troubleshooting know-how. What we don’t always consider is that these costs go beyond pure dollars and cents.
A penny saved is a penny earned
The immediate costs are the most apparent costs linked to maintenance and repairs. These are the actual, unplanned dollars that it costs to repair broken and faulty equipment. Expenses like these often cause the finance team to be up in arms and get them wondering why maintenance is so costly.
In the long term, repeated breakdowns, failures, and stops in production can lead to the need to bring in expensive vendors in for repairs and replacement of the asset.
Being able to troubleshoot well and having all the information you need at your fingertips will give you the leverage to reframe the conversation and relationship. Instead of Finance coming to you wondering why everything you need costs so much money, you can say, “Hey, look at how much we’ve saved you. This could have cost hundreds, if not thousands more”.
Now, as far as Finance is concerned, you’re the hero instead of the villian.
The show must go on
Downtime is expensive — more expensive than just the cost of fixing the machine. When you’ve got equipment that’s broken down, it stops your revenue-producing activities in their tracks. Every minute you can’t operate is more money out the window. The faster your maintenance crew can get running again, the more money you stand to save.
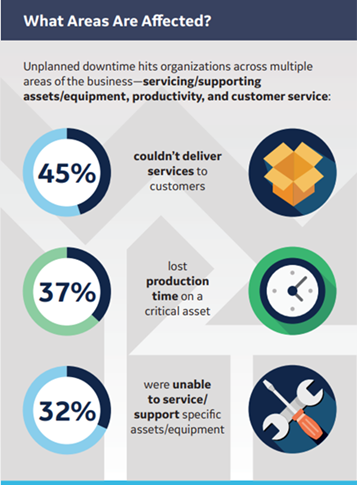
In a study by Vanson Borne of GE Digital for ServiceMax surveying 450 services and IT decision-makers from around the world, they found that:
- Of the 82 percent of companies that have experienced unplanned downtime over the past three years, those outages lasted an average of four hours and cost an average of $2 million.
- Unplanned downtime results in loss of customer trust and productivity — 46 percent couldn’t deliver services to customers, 37 percent lost production time on a critical asset, and 29 percent were totally unable to service or support specific equipment or assets.
Your reputation on the line
Continued breakdowns and halts in production can lead to reputation damage and a lack of trust from your team and customers. If your company can’t guarantee delivery of products and services, your customers will go to someone who can.
When employees cannot do their jobs because the equipment they need doesn’t work and cannot get help, they get frustrated. Losing customers can eventually mean job cuts. No one wants to work in a place where there is job uncertainty.
But when you’ve got a maintenance crew that’s effective at troubleshooting with a great system to back them up, they help uphold your company’s reputation, which helps drive brand loyalty.
[limblequote]In 2019, California’s Pacific Gas and Electric was forced to cut power to over 2 million people to finally catch up on deferred maintenance that they hadn’t gotten to for years. The lack of maintenance was proven to have led to the downed power lines that caused two dozen deadly wildfires. More than likely, there were minor problems along the way that, if caught, could have aided in avoiding these disasters. PG&E later filed bankruptcy after being held liable for tens of billions of dollars in damages. [/limblequote]
When we don’t troubleshoot effectively, problems get worse. Things pile up, and maintenance becomes reactive, not proactive. Things slip through the cracks or are brushed under the rug, which can lead to devastating consequences.
Replace or repair dilemma
It sometimes makes more sense to replace equipment instead of repairing it. But, it isn’t always easy to ask the finance department to shell out money for new equipment, especially if it wasn’t part of the original budget.
By tracking maintenance and repairs in a CMMS with functional reporting, you can produce factual information about the planned and unplanned maintenance, costs, frequency of breakdown, and loss of productivity of any asset.
Limble’s custom reporting will help you tell the story more easily to your friends in Finance. You can measure how much downtime an asset is causing and how much that is costing the company. Show that to Finance, and all of a sudden, the argument is easily won. The cost of replacement is justified.
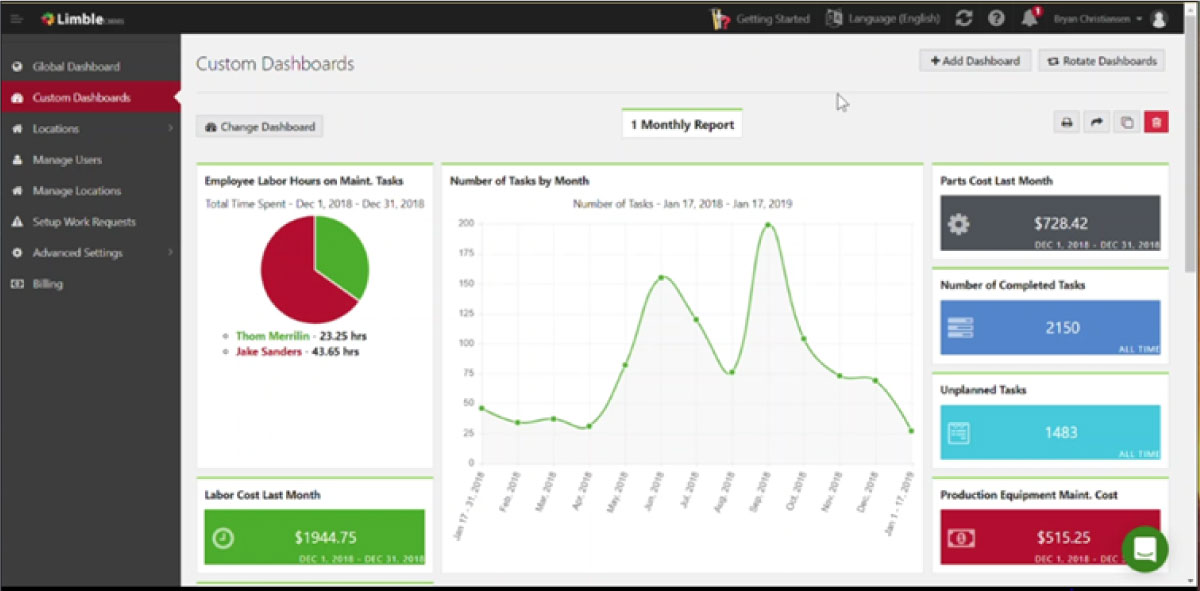
Example of a custom dashboard in Limble CMMS
Troubleshooting the same device over and over can be extremely annoying. Having data to backup your recommendation for replacement can save everyone a lot of time, money, and headaches.
Free Essential Guide to CMMS
Discover everything you need to know about CMMS in this comprehensive guide. Begin your maintenance journey now!

Who performs troubleshooting?
Often, the most experienced technicians are the ones doing the troubleshooting. Unfortunately, 60% of these maintenance professionals are retiring in the coming few years.
What makes these technicians so good at what they do? Many of them have learned through trial and error what are the best troubleshooting techniques for each piece of equipment. There is massive value in having those senior technicians running the troubleshooting teams and creating checklists that hit on the most common issues.
The problem is that when all these experienced technicians retire, they take their knowledge with them. There is already a big labor shortage in the industry. Suppose we haven’t codified the information into a central hub (like Limble). In that case, we risk losing valuable historical info when they leave.
Limble’s ability to track historical knowledge of assets makes it easy for a technician to see the entire work history of the asset. Users can also add notes and “quirks” about the machine that would usually take a lot of trial and error to uncover, saving a lot of time.
Depending on the complexity of the machine, your maintenance crew can train experienced users for straightforward troubleshooting tasks. They will need to perform visual checks, general troubleshooting, and other maintenance tasks to do this. It is an approach known as autonomous maintenance.
If users or operators are troubleshooting, you need an easy-to-understand, user-friendly method for collecting and saving as much information as possible. This can make current and future repairs far less complicated.
All this info (work order, maintenance history, checklists, manuals, etc.) lives inside Limble CMMS. Having the right information easily accessible can significantly speed up the troubleshooting process.
Troubleshooting steps
Troubleshooting is a step-by-step process. Below, we break it down into six simple to follow steps. It doesn’t matter if you are an advanced or inexperienced professional; you will follow the same systematic approach every time.
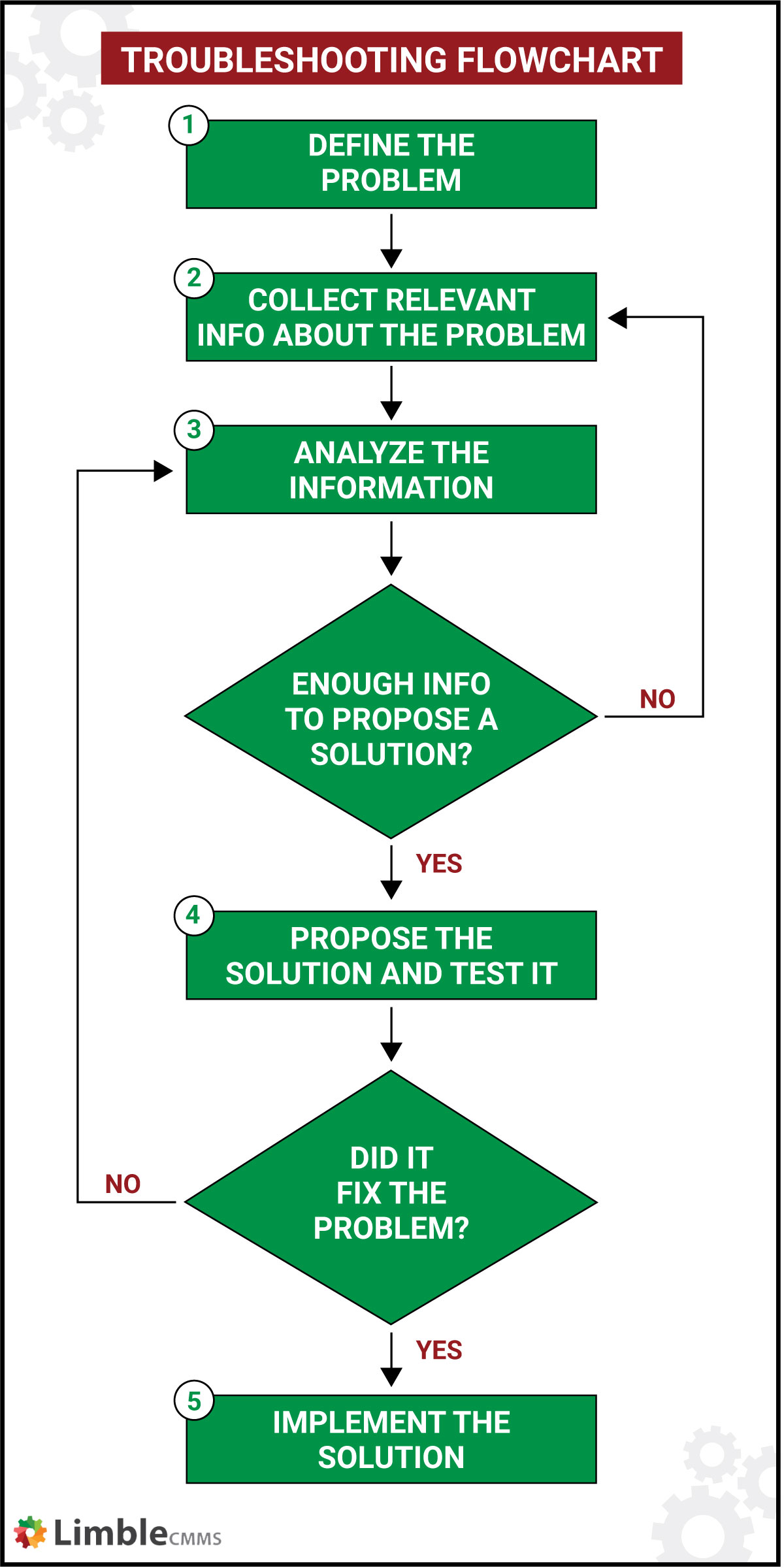
Step 1: Define the problem
The first step of solving any problem is to know what type of problem it is and define it well. A clear definition is fundamental when troubleshooting.
When looking at a problem, you need to know what you are up against and the possible causes. Is it machine failure, an unexpected operation, user error, or a random anomaly? What happened that alerted you to the problem?
Some equipment will have built-in ways of letting you know; alarms can sound, red lights flash, or a warning can go off when certain parts overheat. These signals can help with problem-solving. Other equipment just stops working.
Whatever the case may be, you have to identify and define the problem before you can move forward.
Step 2: Collect relevant information
You need to gather all the available information about the machine and its operations. You’ll need the machine manual, any data regarding operations. For example, how often the machine is used, by whom, for what, and how long. You will also need the maintenance history, problem reports, etc.
A modern CMMS like Limble should have the option to keep a digital copy of all the documents, history, and information. If communication with the Original Equipment Manufacturer (OEM) is possible, the maintenance crew can discuss the issue first. Sometimes calling the OEM is the fastest and easiest way to get the right help.
Step 3: Analyze collected data
Using all the information you have gathered, available checklists, and as much technical know-how as you can muster, you can now try to determine the root cause of the problem. Seek out expertise from other maintenance troubleshooters or the person who reported the fault. It’s much easier to solve a problem that you have seen before.
Think about recent changes to the asset. Ask yourself:
- Did we use new replacement parts?
- Has there been an upgrade lately?
- Did we change the type of input material we use?
- Has the device been used in a different way than usual?
- Has there been an electrical surge?
Recent changes to the system or environment can often explain why the problem has come up.
If you still have no clue what caused the problem after analyzing the data, you need to go back to Step 2 and collect more info. It is possible to overlook things or disregard something as unimportant during the first round of the information-gathering process.
After this exercise, the person performing troubleshooting should form an educated guess and put forward some solutions.
Step 4: Propose a solution and test it
Using what you know from above, you can create your plan of attack. You will get to the solution through a process of elimination and trial and error. In some cases, you may be able to test your theory on a smaller scale asset. You may have multiple options to try. Start with the simplest one first and work from there.
Take the following into account:
- potential safety concerns
- all the required resources and associated costs
- how complex the implementation will be
- the long-term outlook for the machine
- any personal biases person performing the troubleshooting may have
Keep testing until you are sure that you have found the right solution. If nothing works, you will need to rethink what the actual cause is.
Step 5: Implement the solution
Once you have accurately diagnosed the problem, found the solution, and tested it, it’s time to get your hands dirty and fix it. Even if your solution worked during testing, it is important to test it again. Ensure the asset is working the way it should before you pack up and sign off. You’ll also want to make a note of all the steps you take as you make them, so you don’t forget what you’ve done.

Bonus step: It’s fixed! You’re a hero! Now what?
It sounds obvious, but it is crucial to document the solution and add it to the asset log in your CMMS. It’s easy to get carried away working and forget to document your findings. “Ah, I’ll do it next time,” you might think. But what if you don’t remember next time?!? Then we’re in trouble.
As you’re going through the process, take the time to do it right and save yourself the trouble next time.
A practical maintenance toolkit holds as much information about an asset as possible. In Limble, tracking an asset’s history is ridiculously easy. You can see all related Work Orders, Parts, who did work most recently – you can even manually add notes and images taken with your phone.
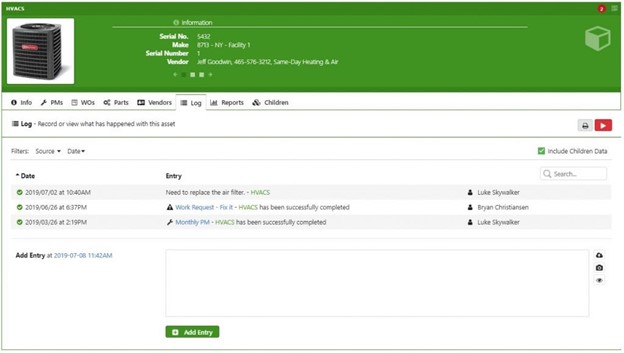
Example of an asset log entry in Limble CMMS
By keeping a record of every step, from reporting the fault or failure to the five steps above, you can create a clear path through the troubleshooting journey to repair or, in some cases, show the need to replace the asset.
Imagine how easy it will be to fix if the problem happens again!
Ways to make troubleshooting easier
We are here to make your job easier. When it comes to troubleshooting, it can feel overwhelming and disorganized.
There are many tools available to help you and your crew get to the bottom of any problem. Below are a few of the commonly used tools and resources for effective troubleshooting.
Troubleshooting checklists
Checklists are a great way to approach common problems methodically and help standardize the process. They do the heavy lifting for you. When you’ve got a lot going on it can be risky to rely on your own brain to remember all of the steps. Having a checklist means that you don’t have to.
Maintenance platforms like Limble also let you create and store troubleshooting checklists that can be accessed on mobile devices and used in the field.
Maintenance engineers can work with experienced technicians to identify problematic assets and create step-by-step troubleshooting instructions that include warnings and images for specific assets/issues. When you finish, you can attach each checklist to the corresponding piece of machinery.
A modern CMMS
Having the right CMMS can streamline, organize, and automate your maintenance
operations. A modern CMMS will save you and your team time and your company a lot of money.
As a centralized repository of maintenance data, a CMMS keeps a lot of helpful information used during the troubleshooting process like:
- OEM manuals
- contact information for machine and parts vendors
- maintenance logs and reports
- details of the work request sent to report the problem
- troubleshooting and other maintenance checklists
- past and current machine-condition and performance data gathered through CBM sensors
[limblequote]Limble CMMS uses QR codes to give your users easy access to all the information about the equipment with a simple scan of their phone. They can scan the code on the side of the equipment and quickly report faults to your team with the correct asset already attached to the work order. [/limblequote]
Having quick and easy access to this information can significantly speed up the troubleshooting process and reduce the loss of institutional knowledge when technicians retire or move on. These are just a few of many reasons why more and more organizations are implementing cloud-based maintenance solutions.
The future of troubleshooting
Factories are becoming more automated, and machines need fewer operators. Because of these changes, the number of technicians required for troubleshooting and equipment maintenance is growing.
Luckily, technology is making troubleshooting easier, faster, and less dangerous. Here are some solutions that are making their way to many plant floors.
A robot with a crystal ball
Can you imagine a world where computers fix themselves? Machine learning is a step towards this. It gives systems the ability to learn and get better at things without being programmed. It can help predict possible problems and is a big part of predictive maintenance.
When it comes to troubleshooting, machine learning is helping us analyze large amounts of data and identify/predict possible causes of faults and failures.
Some organizations are already taking things a step further and testing something called prescriptive analytics. In the context of troubleshooting, prescriptive analytics aims to help machines diagnose themselves and then present possible solutions based on that self-diagnosis.
Enhancing the real world with AR
Augmented reality (AR) combines computer-generated imagery with the actual equipment to give an additional layer of information. You can overlay parts and look into things that you ordinarily wouldn’t be able to.
All you need is a phone or tablet loaded with the software. Hold it over the machine, and the program will pull up all the different layers for you to look at.
If you are in the middle of a diagnosis, this can be a great way to check if everything is where it should be or make sure that it is in good working order.

Augmented reality in quality control. Source: Metrology.news
AR allows your maintenance team to see all the information about a component on the screen. It can also show you tips, warnings, and next steps, improving quality and safety during the troubleshooting process.
Simulations and virtual reality
Thought AR was cool? Check this out.
Virtual Reality (VR) takes you into a world of endless possibilities as you are whisked into a simulated environment of the machine you are working on. In this virtual environment, expensive equipment can’t get damaged, and you can’t get hurt.
It’s a great way to learn, play, experiment and practice before having to return to the real world to fix the actual machine. You can have a 100% immersive experience fixing things. It’s like turning your job into a video game.
Digital (non-evil) twin
A digital twin is a virtual copy of your machine. The sensors installed on your machine send data about its condition and performance. This cloud-based copy analyzes this data (that is coming from dozens or hundreds of different production floors that use the same type of machine) and uses it to advance technology, predict failures, and find ways to repair problems from a distance.

Digital twin in manufacturing. Source: Siemens
If a failure happens at your location, the OEM can compare it against the data from all the other machines of the same kind. Based on the meta analysis, the OEM can identify if a similar incident happened to a machine at some other plant – and propose a potential solution.
Troubleshooting: A maintenance professional’s best friend
In the best-case scenario, a malfunctioning device will result in a mild annoyance. In the worst-case scenario, it can cause a safety incident and have a debilitating effect on a business’s bottom line.
If you have any troubleshooting questions, jump to the comment section below. If you want to learn more about Limble CMMS, you can contact us directly or start a free trial.
