Equipment or system failures can take a number of different forms and have varying consequences. But whether full or partial, minor or catastrophic, they all impact a business’s productivity and operations. Understanding failures and examining how we respond to them is the only way to minimize their negative impact. That is the value of failure metrics.
In this guide, we will review the most useful and commonly used failure metrics, and set you up to use them within your organization. In no time, you’ll have the data you need to update your maintenance processes and reduce the work stoppages associated with system failures.
What are failure metrics?
Failure metrics are a set of calculations that measure the average time a team or organization spends addressing and resolving system failures or their frequency. System failures may be machine breakdowns, power outages, or any other incident that causes a system to fail to perform its function, resulting in interruptions to operations.
Benefits of tracking failure metrics
Even organizations with the most efficient and effective maintenance teams will eventually experience equipment failures. Equipment failures cause downtime, emergency repair costs, and lost revenue.
That is why tracking failure metrics and planning for failures is critical. Through planning, organizations can help reduce the length, cost, and overall impact of downtime. Calculating failure metrics provides a number of other benefits such as:
- Improved asset reliability and lifespan
- Reduced maintenance costs
- Better quality control and fewer defective products
- Safer and more productive workplace
- Improved asset management and efficiency
The most common failure metrics in maintenance: MTTR vs MTBF vs MTTF
Tracking a few common failure metrics eliminates guesswork, helps maintenance managers improve their teams’ response to failures, and minimizes operational disruptions. The three most common are:
- Mean Time to Repair (MTTR)
- Mean Time Between Failures (MTBF)
- Mean Time To Failure (MTTF)
The data points used to calculate failure metrics
Data is important but collecting and analyzing it can sometimes feel overwhelming. The good news is that calculating failure metrics is pretty simple, and only requires three key data points that most organizations can find in their maintenance histories.
- Labor hours spent on maintenance: The amount of time it takes to complete each maintenance work order, along with the dates they were performed.
- Number of breakdowns and repairs: The number of system failures that occurred within the time period you are measuring.
- Operational time: The expected or planned operating hours within the time period you are measuring.
Maintenance teams likely already document this information on paper, in spreadsheets, or more commonly, directly within software like a Computerized Maintenance Management System (CMMS). Most CMMS systems can track these numbers and calculate failure metrics for you automatically.
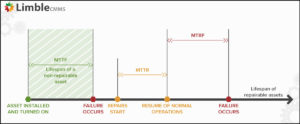
What is MTTR?
Mean Time To Repair or MTTR is the average time it takes to complete a repair from start to finish. It tells a team how quickly it is responding to asset issues and failures.
By having a high-level overview of how long repairs generally take, maintenance managers can:
- Understand how much time should be allowed for repairs
- Coordinate workloads for team members to ensure enough resources are available
- Find patterns by location, production line, asset, or team member
- Identify, investigate, and troubleshoot outliers to reduce the impact of the most costly events
Why MTTR is important
Repairs equal downtime which has a huge effect on productivity and business results. In a manufacturing environment, long mean time to repair leads to missed production deadlines, increased labor costs, loss of revenue, and various operational issues. In a facility management environment, excessive mean time to repair can seriously impact customer satisfaction, safety, and legal risk.
How to calculate MTTR
MTTR is calculated by dividing the total maintenance time in a given period of time, by the total number of repairs performed in that same period. This information can then be segmented based on other available data points important to your organization like team member or location.
For instance, if your team is deployed 5 times in one week to repair pumps on a production line, and your records show that your team has spent a total of 3 hours (180 minutes) that week repairing pumps, the MTTR for that week is 36 minutes.
MTTR = 180 minutes of repair time / 5 total repairs
MTTR = 36 minutes
Although each individual repair time may vary, this calculation provides a general idea of how much time is spent on each pump repair.
Keys to improving MTTR
The primary way to improve – or lower – MTTR, is to make sure maintenance processes are as efficient as possible. That requires going back to the basics and shoring up things like:
- Spare parts and asset inventory management practices that make parts and equipment information easily accessible
- Standard operating procedures (SOPs) and maintenance checklists that streamline repairs
- Technician training that ensures team members are prepared to quickly and effectively decipher failure modes and respond to problems
- Technology and condition monitoring devices that can help provide context and shorten troubleshooting processes
What is MTBF?
Mean Time Between Failures or MTBF is the average time that passes from the end of one repair to the next failure. It tells a team how long a piece of equipment might be expected to run between unplanned breakdowns, and helps them plan for the unexpected.
By having a general idea of how long machines or systems tend to run in between failures, maintenance managers can:
- Understand how frequently repairs might be needed
- Coordinate workloads for team members to ensure enough resources are available
- Assess and improve the effectiveness of repairs at keeping systems operational
- Determine the frequency of preventive maintenance inspections and maintenance activities that may prevent or stave off failures
Why MTBF is important
Unlike MTTR, the goal is to ensure an MTBF that is as long as possible. The longer a system or asset goes without a failure, the more it is able to produce. In addition, each asset failure runs the risk of downtime losses, workplace safety incidents, and irreparable damage to equipment. Reducing the frequency of these events dramatically reduces the risks – and costs — to the business.
How to calculate MTBF
MTBF is calculated by dividing the total operational time in a given period of time, by the total number of failures that occurred in that same period of time. This information can then be segmented based on other data points you have available such as location, asset type, and more.
Taking the example from above, if a specific pump on a production line fails 5 times in one week, and that pump’s total run time that week was 80 hours (or 4,800 minutes), the MTBF for that pump for that particular week is 16 hours (or 960 minutes).
MTBF = 4,800 minutes of operational time / 5 total failures
MTBF = 960 minutes
On average, that pump has failed – and can be expected to fail – every 960 minutes.
Keys to improving MTBF
The primary way to improve – or increase – MTBF, is to make sure maintenance processes are as effective as possible. Keeping assets in good working condition with precise preventive maintenance is key through things like:
- Effective and well-executed preventive maintenance work
- Using high-quality replacement parts in maintenance and repairs
- Properly training machine operators to ensure optimal operating conditions and input materials
- Take extra care with aging equipment, reviewing asset logs and maintenance histories when performing maintenance work
What is MTTF?
Mean Time To Failure or MTTF is the average length of time a non-reparable item is expected to last until it needs to be replaced. It represents the lifetime of a single-use product or device, and is calculated by analyzing the performance of a large quantity of that item over a particular period of time.
By having a high-level overview of how long a non-repairable system component is expected to last, maintenance managers can:
- Plan spare parts inventory with greater accuracy
- Evaluate parts makers and vendors based on the quality or reliability of their parts
- Predict and prevent larger system failures based on the MTTF of their non-repairable components
- Plan replacements and other preventive actions with greater accuracy
Why MTTF is important
Similar to MTBF, steps should be taken to ensure MTTF is as long as possible in order to prolong and maximize production time. Doing so ensures higher output, and minimizes risks associated with frequent failures like workplace safety incidents, and irreparable damage to equipment.
How to calculate MTTF
MTTF is calculated by dividing the total operation time in a given period of time, by the total number of items used in that same period. Again, this information can then be segmented based on other data points you have available such as item type, purpose, or manufacturer.
For instance, if the pump from our previous example ran for 80 hours (or 4,800 minutes), but a specific gasket on the pump had to be replaced 2 times in that same period, the MTTF for that gasket is 40 hours (or 2,400 minutes).
MTTF = 4,800 minutes of operating time / 2 total gaskets
MTTF = 2,400 minutes
This calculation provides a general idea of the longevity that can be expected of different kinds of consumable or non-repairable items. In this case, if a more expensive gasket from a different manufacturer has an MTTF that is twice as long, a maintenance manager can now evaluate whether or not the additional cost is worth the improved MTTF.
Keys to improving MTTF
Because these are non-repairable items, the steps your maintenance team can take to extend their MTTF are minimal. The primary way to improve – or increase – MTTF, is in how these kinds of items are chosen and used.
- Pay attention to item quality when sourcing non-repairable components
- Ensure proper preventive maintenance on the larger assets where these non-repairable items are installed
- Ensure that these non-repairable items are installed, stored, and used properly and within OEM parameters
More failure metrics
There are a number of other failure metrics that can help provide context to your maintenance practices. MTTF, MTTR, and MTBF may be three of the most common, but organizations should consider others to gain a broader picture of their maintenance operations, such as:
- MDT (Mean Down Time): The average time a system or asset remains down once a failure has occurred.
- MTTD (Mean Time to Detect): The average time it takes machine operators or other personnel to detect and report a failure.
- MTTA (Mean Time to Acknowledge): The average response time by the maintenance team, once a failure occurs.
- MTTI (Mean Time to Identify): The average time it takes your team to identify the root cause of a failure so they can begin a repair.
Choosing (and using) the right failure metrics
While each failure metric provides its own benefits, the real insights come from applying multiple failure metrics to your maintenance operations. By monitoring and working to improve all three (or more) failure metrics, organizations let the data point to the biggest opportunities for improvement.
If tracking multiple failure metrics sounds complicated, numerous solutions exist to streamline the process. Create a Failure Metrics Calculator or implement a Computerized Maintenance Management System (CMMS) that will calculate, track, and analyze these metrics for you.

greetings:
Regards, please explain my three questions about the MTBF and MTTR Indicators.
1. According to the formula for calculating the MTBF index, which is equal to the total operating time of the device divided by the number of emergency repairs in a specified interval, when the machine is healthy and not working, this time is considered as the working time and used in the calculation of the index. Or not?
2. How to calculate the MTBF index for a device that did not have any failures or emergency repairs during a one-month period?
3. How to calculate the MTTR index for several different devices in a given time period, such as one month?
Hi M.IRANI!
Those are some specific situation but I’ll try to help as much as I can.
1. You should not take into account the time when the machine is not operational as that wouldn’t give you a clear picture of how much wear and tear a machine can take before breaking down. You should include any time the machine is operating, healthy or not.
2. In those scenarios it may be best to get a MTBF index for a group of similar assets. That way you can measuring healthy assets with your problem assets and can have a good measurement of when you will likely experience a breakdown.
3. You need to look at each device and make a total sum of the time spent to repair and restore it normal operating conditions and then divide it with the total number of repairs that the device had. This data is obviously hard to accurately track manually so we set up Limble to calculate that automatically (as long as your technicians enter the time they’ve spent on the repair).
I hope this helps!
Hi,
I have a query here. You mentioned that we should not take into account the time when the machine is not operational. So on the same context what is your thought on Starved and Blocked times on the MTBF of an equipment ? We term it as internal MTBF while dealing with the failure analysis at Equipment failure level and not system level.
So should we exclude starved and blocked times while doing the mtbf analysis because in these 2 states even though my machine is availiable it is not processing anything i.e its in idle state. Appreciate your insights on this !
Vivek D – +91-9900290780
[email protected]
Hi Vivek!
Great question.
The answer is… it depends. In most situations I would personally not include the “Starved and Blocked” times since the machines are not being used and therefore the majority of the wear and tear is not occurring.
That being said the most important thing is to be consistent and clear with which way you choose to measure. If one month you take include the “Starved and Blocked” times, but the next don’t you will run into inconsistent data. Therefore you should made it very clear for your company’s best practices you are or are not including the “Starved and Blocked” times.
Another factor to consider is how other teams outside of your own consider what times to include when calculating how long an equipment is running. They may consider the equipment running even when it is in a “Starved and Blocked” time while you don’t. For example, if you tell production to expect a machine to break every x hours of running, yet they think a machine is running even during “Starved and Blocked” times you will cause confusion which will cause problems.
I hope that helped answer your question… If not let me know!
If MTTF of single processor is 10000 hours. What will be MTTF of 1000 processors? Assuming if one fails, they all fail.
my answer is 10 hours is it correct? Explain plse aslo
How do we determine the index factor between MTBF and MTTR
It is possible to calculate the MTBF and MTTR when only occurred 1 failure during the working time period of the machine?
Hi Mariella,
For MTBF, you need at least 2 failures to calculate “time between failures”. Keep in mind that basing any decision on just one small sample like this might not give you the most accurate information.
As for MTTR, you can technically calculate it with only one failure. But again, calculating “mean” in “mean time to failure” implies that you are measuring multiple values and calculating an average.
Another point to bring up is calculating these metrics on a group of similar machines so you can get more actionable results if the number of your data points are low.
I hope that clears things up a bit.
Hi Bryan,
MTTR and MTBF is use for calculating every part on the machine (1 part 1 MTTR and 1 MTBF) or 1 machine (any problem part on machine 1 MTTR and 1 MTBF) ?
we need to see the performance of the 20 equipments individually. Failure rates variying from zero failures to 5 and so on. How I can distinguish the zero failure machine performance, one failure machine performance month wise. Please help.
thanku, this is very useful
Thank you and glad you liked it 🙂
Hi Rajiv if you are using a good CMMS you can have it automatically do those calculations for you. Other then that it would be hard to give help without looking at the actual data. Fill free to send it over to [email protected] and we can take a quick look 🙂
Hi Joko, It depends on how you want to set it up. Ideally you should have one report that does MTTR and MTBF for the top level equipment and all of its parts and then also another report for each part of that machine. A good CMMS will automatically do these calculations for you so you know exactly what your MTTR and MTBF is for every granular level.
Hi,
Will you suggest me how to calculate MTBF for multiple equipment in single system?
Example: Petrol station in single city. i want to calculate MTBF of all station having same fuelling pump. How do I calculate the MTBF for whole system or Single station?
Good Morning
I was Reading your Internet page, and it’s very interesting but I have a question about how to calculate MTBF with the Formula, in this moment we calculated MTTR and MTBF every month for every machine, my question is:
If in the last month I didn’t have any fail and the machine was working 150 hours, how I must to use the formula?
150 / 0 = ∞
Could you help me to clarify my doubt please?
Thanks In advance
I have 4 shift , how i calculate MTBF for every shift although every breakdown have adiffrent frequency for every shift.
if i calualte MTBF / month for one shift = working hr per month / no of failures is correct or no although for every shift breakdown have diffrent frequeny of failure.
Hi sir,
Do you have any idea what is repair success rate? is this similar to MTTR?
Good Morning
I was Reading your Internet page, and it’s very interesting but I have a question about how to calculate MTBF with the Formula, in this moment we calculated MTTR and MTBF every month for every machine, my question is:
If in the last month I didn’t have any fail and the machine was working 150 hours, how I must to use the formula?
150 / 0 = ∞
Could you help me to clarify my doubt please?
Thanks In advance
PLEASE THIS QUES VERY IMPORTANT PLEASE ANSWER IT
Hi Omar,
If there wasn’t any failure you can’t calculate MTBF. I’m not sure how you use it at your organization but calculating it on a monthly basis doesn’t seem like the best approach, especially if the machine isn’t “breaking” multiple times a month.
Looking at the overall trend for a longer period of time for every particular machine would probably give you more useful info.
I hope that helps!
Hello,
Thank you for the nice introduction, we would like to adopt this failure indicator as our KPI.
but may I ask as to calculate MTBF the Running time may effect to other non related with Machine. i.e. we are running 24Hrs = 1440 min, and there is Plan D/T for break and change model about 200min. and there is un planned downtime for change parts, set up, change tool and machine problem total about 350 min (in here the D/T is mix and ae we need to segregate?), and machine qty failure is 150 times. can I say that:
– Running Time = 1440 – 200 – 350 = 890 min or 1440 – 350 = 1090 min ?
– Machine Problem Qty = 150 times
so MTBF = 890/150 =6 min 0r 1090/150 = 7.2 min (this based on single machine)
Thank you.
Hello,
Since the MTBF is concerned only with operational time, you should use the first calculation (890/150).
That being said, it might not be a bad idea to track how much of that downtime is planned and how much is unplanned as that will give you a greater insight on what you need to improve or spot potential issues.
Hello,
I would like to verify about MTTF and Predictive Maintenance tracking were both similar to calculation for the spare part Usual life cycle?
Beside there commonly machine maker have the schedule for the replacement of consumable components/ usual life cycle, how we priority the Lean cost saving vs, TPM practical ?
Pls. advice
I would love to help you Alex but I do not really understand the question. If you could explain it in more details, that would really help.
Hi,
Can we use MTBF for daily monitoring of machine/equipments ? and if there is no failure in machine, how to calculate MTBF.
Hello,
MBTF is probably not the metric you would want to use for some kind of daily monitoring. You will be better off making a PM plan based on OEM guidelines and schedule preventive work and inspections accordingly (more info here: https://limblecmms.com/blog/the-ridiculously-simple-preventive-maintenance-plan/)
If you do not have any failures, then you can’t really measure MTBF 🙂
I hope this answers your questions.
Hii sir,
some query.
1 – How to define MTBF a product run time 100days ?
2- How can improved MTBF a prouct service life ?
Hi Bikash,
1. To define MTBF for a product, you need to know how much time did the product spent “in use/operating” for those 100 days and how many times did it fail and then you can use the formula given in the article.
2. MTBF can be used as one of the methods to help you predict when the product might fail so you can schedule preventive maintenance before that happens. The fewer breakdowns an asset experiences, in many cases, the longer the lifespan of that asset.
Not sure if I got your questions right though, I hope I did!
Hello
Thank you so much for this write up. It’s really helpful.
How can a PM plan be built for a daily monitoring machine?
Thanks Andrew 🙂
We actually have an in-depth guide on how to create a PM plan. It includes all the steps you need to now, gives examples, and you can even download a helpful checklist.
I hope that helps!
very insightful.
I am working on calculating the maintenance ratio for two items, discrete numbers for field maintenance and sustainment maintenance. I am focusing the math one a count of one, versus the total number of fielded items. do you think this is the right approach? The MTBF I am using is a projected number, since this is a relatively new piece of equipment.
Thanks for commenting Danny.
It seems like a pretty specific example. I’m afraid my knowledge of the subject matter doesn’t extend that far so I wouldn’t be comfortable giving you advice that might set you on the wrong path.
It does sound like you know what you’re doing though 🙂
Very well explained.
As we all know that theoretically, MTBF = MTTR (repair) +MTTF (failure) but in your article under MTBF section, there is a figure which shows MTTR and MTBF are two different phases. why?
use some simple math:
10,000/1 = 10,000MTTF
(10,000(item1)+10,000(item2)+…+10,000(item1,000))/1,000=10,000MTTF
MTBF does not include the time you spend repairing the asset, you only take “working” hours into account for calculating MTBF.
if there are 10 line of sight microwave links are arranged for a radio receiver. The time availability at the last receiver in the system (due to propagation alone) was found to be 99.82%. Use the most conservative method to find the time availability assigned to each microwave link. Justify how the method is conservative. thanks
Hi Sir,
What is the bench mark for MTTR, MTBF and MTTF for used equipment say 10 yrs old.
That sounds like it was taken from a quiz 🙂
I’m afraid we can’t help you here, but there’s always a chance that other readers of the article help you out!
That vastly varies from one piece of equipment to the other, from working conditions, from how the equipment is handled, etc.
I’m afraid your best bet is to look at respective OEM manuals and try to see if you read any relevant info between the lines (or maybe try to google these benchmark for the machines in question).
Good luck and let us know if you find the answer – to help other readers that might be in the same situation!
Great intro and thanks for sharing. I have a question I’m hoping you can help with, or at least point me in another direction. I have 100 devices that I’m testing and each one has been continuously operating for a different amount of hours. I’ve had 4 fail after operating for 538, 583, 810, and 829 hours. Is the MTTF calculated as (538+583+810+829)/4 or is it all cumulative hours of the 100 devices divided by 100 even though this includes a bunch of devices which haven’t failed yet? My other question is can this data be used to predict what percent of devices will result in failures at a defined time (after 1000 hours for example)? Thanks for your help and insights.
Hello – excellent summary, thank you! A couple of clarification questions: 1. I have data for 134 devices that show how many days they have been operational. There are 4 in there that failed at various times. I’m trying to figure out the correct way to calculate the MTTF and not sure if I do the calculation using only the 4 devices that failed, or if I use the entire data set even though there are devices in there that have yet to fail. I’m also wondering if I can use this data to predict some kind of reliability – something like X% of devices are expected to survive to 500 days, Y% to 1000 days, etc. Can you point me in the right direction on this?
Presuming that we are talking about the same type of device, I would go with your first suggestion “(538+583+810+829)/4”. As more devices fail, you will have a bigger sample and you should be able to use that data to predict how long does a piece lasts on average.
I’m sure there are some statistical equations you can pump MTTF numbers in to try and predict things like which percentage of devices will last for 1000 hours.
Thank you! This is helpful and much appreciated!
Thanks for sharing!!! is there any formulae for calculate the service availability depending upon the MTTR MTBF?
Hi Ashish,
We have this guide for calculating OEE: https://limblecmms.com/blog/oee-overall-equipment-effectiveness/
There we explain how to calculate Availability, hope it helps!
It was a mindclear explanation. I was reading through books but honestly I couldn’t understand anything. You’ve reduced my trouble. Thank You so much sir and keep making such nice article.
Hi , thank you for the summery. i have a question about the number of failures used to calculate MTBF and MTTR .I am in the ambiguity regarding wich stops are considered as failures. Exp : does stop more than 60s considered as a faillure? even overloading , setting, control….ext ?
How to set targets of MTBF , MTTR ?
Thank you in advance.
It is on you to define what you will count as a failure. As a rule of thumb, if it is not something that requires the attention of the maintenance team, I would not count that as a failure.
The stops you mentioned seem like they would play a bigger role in calculating OEE than these failure metrics.
Regarding targets, that depends on the type of device/equipment you’re looking at. Sometimes those numbers might come with the OEM manuals so you know what to expect. Otherwise, you can measure the metrics and then set targets for improvements you think are realistic depending on your available resources.
I hope this helps 🙂
Hi,
Thank you for the summary! I still have some questions:
1. How do you calculate MTBF over more than 1 device? Just sum the different operating hours and divide it by the number of failures? So for example Machine 1 operates for 200hours and fails, machine 2 operates for 300hours and fails, machine 3 operates for 150hours and fails –> (200+300+150)/3
And thus it depends if the machines are set in serial or parallel?
2.And what happens if you have multiple machines, but one of them never fails, do you include them into the calculation of MTBF? For example machine 1 runs for 500hours but never fails, Machine 2 runs for 200 hours and fails and machine 3 runs 100 hours and fails. Does MTBF gets calculated as (500+200+100)/2 or as (200+100)/2
Thanks in advance!
Hi Hanne,
1. You can do that if you want to find an average for the exact same type of device. I would avoid doing that if devices work in different operating conditions as than I do not know how much value would you get from that average number (just something to keep in mind).
Series vs parallel discussion depends on what you want to measure exactly, MTBF of the whole system, machine, or machine components. If it is the system, then the serial vs parallel configuration should give diferent results.
2. I could see an argumeent for using both. Including “500-hours” into the calculation would give you a more accurate average MTBf on such a small sample (with a note that you recalculate it when it eventually fails). If you have a bigger sample, I would not include it in the calculation.
At the end of the day, as long as you understand the context so you do not missread the final number, you’ll be good to go.
Where can I find “typical” MTTF values for components? It appears that noone publishes “true” values?
Thank you very much! Is there actually a standard on how to calculate MTBF for mechanical equipment?
If the OEM manufactures don’t include the numbers (or include misleading ones), I’m not sure if you can get “true values” without testing it for yourself. Maybe try to find other managers that used them and see what was their experience like.
Salam Omar,
from my point of view you need to calculate from your last failure until the moment you report your KPI, e.g
01/01/2020 first start of the machine and the machine works for 390 H then failure at 31/01/2020 , after repair for 10 hours, works for 350 H in 29/02/2020 then the machines works for 390H until 31/03/2020 then no failure and works 390H until 30/04/2020
for the MTBF that you will report will be as below :
Jan/2020 MTBF = 390H
Feb/2020 MTBF = 370H (390+350)/2
Mar/2020 MTBF = 565H (390+350+390)/2
Apr/2020 MTBF = 760H (390+350+390+390)/2
and so on for the others months
If I have I have one equipment which has 2 failures( one is 5.05hrs and 2nd in 2. 5 hrs so how can calculate the MTTF
If one piece of equipment/device had 2 failures then it is obviously an item that has been repaired in the past. MTTF is calculated for non-repairable items (like light bulbs).
You probably want to calculate MTBF or MTTR, not MTTF.